![[couverture de Dossiers Linux 2]](http://www.ed-diamond.com/bigres/ldos2.jpg "Dossiers Linux 2")
Copyright © 2004 - Sébastien Aperghis-Tramoni & Michel Rodriguez.
![[+ del.icio.us]](/images/add-to-delicious.gif)
![[+ Developers Zone]](/images/add-to-dzone.gif)
![[+ Bookmarks.fr]](/images/add-to-bookmarks-fr.png)
![[Digg this]](/images/add-to-digg.png)
![[+ My Yahoo!]](/images/add-to-myyahoo.gif)
Cet article est un inédit publié pour la première fois dans Les Dossiers Linux 2, avril/mai/juin 2004.
Comme vous le savez déjà, les Mongueurs de Perl ont organisé en
juillet 2003 la conférence Perl YAPC::Europe.
Voici un compte-rendu de cette conférence rédigée par deux
auditeurs (attentifs :-)) : un contenu très divers qui ouvre
de nombreux horizons nouveaux voire inatendus, mais en tout cas
très enrichissants...
Nicholas Clark est un type très marrant : il arrive avec un sourire jusqu'au oreilles et un sombrero mexicain et ne départira ni de l'un ni de l'autre durant les trois jours de YAPC.
Son talk est consacré aux techniques d'optimisations de Perl.
Les premières méthodes sont évidemment d'utiliser XS ou Inline.
Il conseille aussi de recompiler son Perl avec plus d'options
d'optimisation (par exemple -O2 ou -Os, ainsi que les
options d'architecture -march=YOURCPU) et moins d'options
de debug (-g et les defines de debug). Autre possibilité,
utiliser une autre version de Perl plus ancienne ou plus récente
suivant les fonctionnalités dont on a besoin et la vitesse
d'exécution constatée. (Selon certaines personnes, la branche
5.005 et en particulier la version 5.005_04 offrirait ainsi
les meilleurs compromis performances/fonctionnalités.)
L'ajout d'optimisations ne devant évidemment pas casser le
code existant ou introduire de nouveaux bugs, il est plus que
recommandé d'utiliser Test, et de mettre en place des
tests de régression avancés.
Vient alors le problème fondamental : comment trouver quoi
optimiser. Devel::DProf et Devel::SmallProf qui permettent
respectivement de faire du profiling de manière globale ou
ligne par ligne, apparaissent tout indiqués. Nicholas conseille de
tricher avec Devel::DProf en découpant une grosse fonction
comportant plusieurs boucles imbriquées en autant de sous-fonctions
(en partant des boucles extérieures vers les boucles intérieures).
L'utilisation de Benchmark est recommandée pour tester les
différentes versions d'un même code pour vérifier de manière
expérimentale laquelle est la plus rapide. En effet l'intuition
peut souvent s'avérer trompeuse (ainsi tr/// est souvent plus
rapide qu'on ne le croit par exemple).
Il expose ensuite comment on peut voir l'arbre des instructions
généré par Perl (-MO=Terse) et fait remarquer le coût des
boucles. « Loops are bad ». Il montre sur un exemple
comment remplacer une boucle basée sur un while et des
expressions régulières par pack().
Nicholas propose quelques petites astuces en vrac, comme
l'utilisation de Devel::Size pour voir la taille mémoire des
objets ou l'emploi de constructions comme /\G.../gc pour optimiser
les expressions régulières. Il rappelle aussi que les modules
AutoLoader et AutoSplit permettent le chargement dynamique
de fonctions afin de gagner du temps à l'initialisation.
Continuant sur cette voie, il enchaîne sur l'importation et
rappelle que c'est un mécanisme intrinsèquement lent puisque
Exporter est écrit en Perl et utilise eval "". La règle
est donc (côté module) de ne pas coder de grosses listes @EXPORT
et (côté utilisation d'un module) de n'importer que ce qu'on
utilise. L'exemple typique d'un module dont il est préférable de ne
pas tout importer est POSIX, dont la liste de fonctions exportées
est très importante.
Conseil intéressant : il montre comment utiliser Memoize pour
stocker le résultat d'une fonction. Évidemment, c'est à réserver
pour les fonctions dont le calcul est non-trivial (et plutôt du
type calculatoire ; de fait il donne un exemple avec une fonction
de Fibonacci). Il indique que le cache peut même être stocké sur
disque.
Nicholas donne quelques techniques générales d'optimisations :
éviter les constructions de chaînes de caractères ;
mettre le maximum de choses en dehors des boucles ;
écrire les petites fonctions en ligne ;
l'utilisation de sentinelles permet d'économiser certains tests (grand classique) ;
trier moins de données ; il donne un exemple où il transforme
grep /machin/ sort @list en sort grep /machin/ @list
Sur l'utilisation des hashes, il conseille de vérifier la qualité
des clés de hachage et éventuellement de les rendre plus courtes
avec pack().
Pour la transmission de données entre processus Perl il rappelle
qu'il est idiot de parser les données en Perl et conseille d'utiliser
Data::Dumper et eval ou Storable.
Il y a eu une référence à Acme::Buffy pendant ce talk :-).
MJD prévient d'abord qu'il a raccourci ce talk à la demande des organisateurs car ils ont souhaité qu'il présente aussi son multi-talk Twelve Views.
Le plan de son talk ainsi que quelques slides sont présents sur sont site web : http://perl.plover.com/yak/tricks/
MJD explique d'abord certains mécanismes internes de Perl.
Il commence avec les stashs, qui sont les structures
internes reliant les variables à leur valeur. À chaque entrée
de la table des symboles (à chaque nom) correspond un stash,
et chaque stash possède sept « points d'attache » qui correspondent
chacun à un type : scalaire ($), liste (@), hash (%),
code (&), filehandle et format. Et le septième point
d'attache est le typeglob (*), qui permet d'accéder à
tous les types d'un coup.
Cela permet de faire des aliases entre les variables, soit de manière globale :
soit de manière spécifique à l'un des types :
MJD présente encore quelques astuces bien sioux et passe à la partie suivante.
MJD rappelle d'abord les bases de ce mécanisme très utile de Perl
qui permet de charger voire de créer des fonctions à la demande.
Il présente ensuite la forme magique de goto, qui contrairement
à un appel de fonction classique n'effectue aucune opération
de sauvegarde sur la pile mais remplace la fonction courante
par la fonction qu'on invoque.
Il expose ensuite comment utiliser AUTOLOAD et le goto
magique pour générer automatiquement des accesseurs de manière
efficace.
Enfin il présente NEXT.pm, un module complètement fou de
Damian Conway, qui permet de faire quelque chose de semblable
à AUTOLOAD mais sur plusieurs niveaux de classes afin de
gérer des cas complexes d'héritages multiples. (Regarder le schéma à
http://perl.plover.com/yak/tricks/samples/slide094.html
pour mieux visualiser la chose). Quelqu'un du public demande
si cela gère les cas où A dérive de B qui dérive de C
qui dérive de A (oui c'est circulaire). MJD est interloqué
et fait remarquer qu'il n'est même pas capable de représenter
ça au tableau et encore moins de comprendre comment Perl (ou
même un humain) pourrait faire fonctionner une telle chose :
par où commencer la résolution de nom ?
Pour plus d'informations sur NEXT.pm, consulter sa page de
manuel. On peut noter que NEXT.pm est inclus en standard
dans Perl 5.8.
MJD présente enfin rapidement les filtres de sources
Filter::Util::Call et Filter::Simple, des modules
diaboliques qui permettent de modifier le code source
du programme avant sa compilation. Il donne comme exemple un
filtre qui décode un source écrit en ROT-13.
À noter que ces monstruosités^Wmodules font aussi partie
de la distribution standard de Perl 5.8.
Il s'amuse ensuite à nous montrer comment écrire un programme qui ne compile que les jours de pleine lune.
Dans ce multi-talk, MJD nous parle de 12 points divers et variés sans rapport particulier entre eux voire même sans rapport direct avec Perl.
MJD nous explique comment il a écrit un programme qui générait toutes les permutations possibles d'un objet composé de triangles. Il avait obtenu 63 configurations différentes. Il nous montre le résultat, un écran sur lequel on voit 64 configurations, et nous met au défi de trouver lequel est en double. Il explique ensuite comment il a conquis le cœur de sa bien-aimée grâce à ça.
MJD décide maintenant de râler un peu contre les gens qui disent
qu'utiliser system() ou les backticks c'est mal parce que ça
prendrait trop d'instructions. Il fait remarquer que certaines
choses sont plus compliquées à programmer en pur Perl qu'avec
quelques commandes shell bien utilisées et rappelle que Perl est
un langage de glu et qu'un programme simple et lisible est préférable
(et moins sujet à erreur).
MJD décide maintenant de râler contre ceux qui lui écrivent en
demandant s'il a abandonné Text::Template parce qu'il n'y a pas
eu de version dans les N derniers mois. Il se demande pourquoi
les gens ne semblent pas comprendre qu'il ne fait pas de nouvelle
version pour la bonne et simple raison que ce module est parfait.
Il indique le coupable de ce lamentable état d'esprit : Microsoft
(le public est déchaîné).
MJD s'interroge sur la raison qui expliquerait la répugnance des
programmeurs à créer des sous-classes des modules disponibles
sur le CPAN. Il prend là encore comme exemple Text::Template.
Beaucoup de personnes lui demandent de rajouter telle ou telle
fonctionnalité et lui répond que ce serait tout aussi simple pour
eux de créer une sous-classe de Text::Template et d'ajouter la
ou les fonctionnalités qu'ils veulent.
Il suppose que cette répugnance provient d'une lacune dans la documentation : il faudrait que les auteurs de modules et de classes indiquent une API qui devrait rester stable au fil des versions, afin d'établir un genre de contrat moral avec les programmeurs.
strictMJD râle maintenant (décidément, il râle beaucoup dans ces
talks ;-)) contre les gens qui disent aux newbies de mettre
use strict sans leur expliquer ce que cela signifie.
Il explique comment il a reçu des mails curieux, comme un étudiant allemand devant écrire un mémoire et lui envoyant un mail du genre « pourriez-vous m'envoyer des informations sur votre système légal aux USA. C'est très pressé car je dois terminer pour dans moins de deux mois. Merci ». Il se contient avec peine tellement c'est burlesque.
Une note amusante : il se rend compte au milieu de la présentation qu'il a oublié de copier certains des fichiers (MJD n'a pas de portable mais en a emprunté un à un des organisateurs) et se prend des erreurs 404 (fichier non trouvé). Il cherche un peu, puis réclame un portable avec la connexion réseau. Quelqu'un avec un portable sous Windows se propose, mais son réseau ne marche pas. MJD déclare forfait et passe au point suivant.
Le conseil de MJD pour devenir meilleur (et surtout meilleur que les autres) : lire les livres que les autres ne lisent pas et lire les sources. Ce dernier terme doit se prendre au sens général car ce conseil s'applique dans tous les domaines, tant littéraire que philosophique, religieux et éventuellement informatique. Il donne comme exemple qu'au lieu de lire les commentaires de quelqu'un sur les écrits d'Einstein, il vaut mieux lire Einstein directement.
MJD explique la théorie de la complexité. Après une introduction sur les bases de la complexité, il rappelle que même pour un problème NP-complet, on peut toujours obtenir des solutions approchées d'une précision suffisante.
Il explique en quoi il trouve que l'attitude des gens qui répondent
aux questions des newbies par un RTFM (ou par la version à peine
déguisée perldoc perlfunc) est négative. Son conseil : donner
la réponse et indiquer où trouver des informations complémentaires.
Sauf erreur de ma part, il a sauté ce point.
Mais de toute façon, Lisp, on s'en fiche ;-)
MJD veut nous montrer un truc amusant qu'il a trouvé sur le web :
un type qui a réalisé plusieurs parodies du message envoyé en 1974
vers l'amas globulaire M13 depuis le radiotélescope d'Arecibo.
(On peut trouver une version expliquée du message originel à
http://www.fourmilab.ch/goldberg/setimsg.html, ainsi qu'à
http://amo.net/Contact/ où il y a aussi une « réponse » ;-)
Il montre plusieurs des dessins (qui sont très drôles) et commence à discuter le plus sérieusement du monde des fautes « d'orthographes » et du choix des messages et des dessins servant à les représenter. Le public est mort de rire.
Là encore lorsqu'il veut cliquer sur un des dessins MJD se rend compte qu'il ne l'a pas copié non plus. Il réclame encore une fois un portable. Quelqu'un lui donne un portable sous GNU/Linux. Ça marche ! Tonnerre d'applaudissements pour le pingouin !
MJD se connecte sur son site et après avoir entré une URL « secrète » et tapé un mot de passe (on entend des « ooh » dans la salle) trouve enfin les fichiers qui lui faisaient défaut. Il affiche l'image qu'il propose d'envoyer aux extraterrestres. Nouveau tonnerre d'applaudissements.
MJD se demande ce qu'est un langage « fortement typé ». Il montre les résultats de ses recherches sur le net qui donnent à peu près ça :
« Ada est un langage fortement typé, contrairement au C »
« C et Pascal sont fortement typés »
« ... un langage moyennement typé comme le C ... »
« SmallTalk est fortement typé »
« les langages fortement typés comme C ... »
etc.
En bref, personne ne sait ce que c'est mais beaucoup de monde croit dur comme fer à sa propre définition.
Dave commence par décrire l'excellent Tie::Hash::Cannabinol (ou
THC), qui malheureusement n'est pas légal en France (mais si vous
trouvez un serveur en Hollande, c'est probablement valide là bas).
Il présente ensuite son plan : il va débuter par les bases et réserve les aspects les plus rusés après la pause café (pour qu'on tienne le coup).
Il montre ainsi comment surcharger l'interprétations des
constantes : dans son exemple, un module implémente un objet
pour les fractions en stockant le numérateur et le dénominateur,
ce qui permet d'écrire du code comme my $half= '1/2' ou
my $three_quarter = '1/4' + '1/2', où les constantes sont
transformées en objets. Très cool !
Il a d'ailleurs publié la veille sur perl.com un article consacré à ce sujet.
Dave remplaçant en réalité le cours sur SVG de Ronan Oger (ce dernier ayant manqué son avion), il complète avec une autre présentation.
Dave présente un script qui lui permet d'utiliser son portable (son téléphone portable !) pour piloter sa machine. Il compare ça à la même chose en Applescript, bien plus compliqué.
Il fait la démonstration et contrôle Xmms, Galeon, Blast. En fait, il pilote même sa présentation depuis son téléphone. Il ne reste plus qu'à écrire quelques menus intéressants et on pourra diffuser ça à grande échelle et « Take Over the World ». Yipee !
Ca marche avec un Ericsson, probablement grâce au module
Device::Ericsson::AccessoryMenu.
Information Architecture n'est que vaguement défini (ce n'est pas un commentaire désopilant du compte-rendeur mais c'est bien Simon qui le précise), mais comme il y a un bouquin d'O'Reilly dessus, c'est que ça doit bien exister !
Son talk va donc essayer de définir ce concept plus précisement. Si je comprends et si je retranscrit correctement, vous aussi vous saurez employer ce nouveau buzzword et épater votre famille, vos copains, votre chef...
Donc attention : Le paragraphe qui suit est quelque peu long et touffu.
Simon cause donc de la différence entre données et
information. Le programmeur s'inquiète de l'origine des données,
et l'architecte de là où l'information va. Il est important que
concepteurs et programmeurs communiquent entre eux. En tant que
programmeurs nous devons essayer de ne pas oublier pour qui nous
développons. Nous devons aussi essayer de coder proprement les cas
limites (pour que le code ne plante pas) et créer des interfaces
intuitives mais qui ne brident pas les utilisateurs (qui ne sont
pas stupides d'après lui (on ne doit pas avoir les mêmes ; à mon
avis il a piqué tous les utilisateurs intelligents et il n'en restait
plus pour moi ;-))).
Ne pas créer une attitude « Nous contre Eux », en fait c'est
« Nous Tous contre le Marketing ! ». Le rôle de l'Information
Architect est de faciliter tout ça.
À Greg McCarroll, présent dans le public, qui demande pourquoi créer une nouvelle race alors que ce devrait être quelque chose que les codeurs et les concepteurs devraient faire, Simon répond qu'en pratique, ça marche. Le besoin pour ce rôle existe vraiment, mais cela n'empêche pas un chef de projet de remplir cette fonction.
Piers commence devant un écran vide et nous fait applaudir à tout rompre pour que les gens de la salle à côté (où MJD donne son cours) soient jaloux. Ça marche, sur IRC Leon demande ce qui se passe.
Piers enchaîne en réalisant un poney avec une baudruche. Fascinant. La crinière surtout. Applaudissements.
Ca commence bien, le Mac sur lequel il a sa présentation a des problèmes.
Piers expose les techniques de refactorisation.
Il remplace une série de if dans une classe par du polymorphisme
avec double-dispatch. Le problème est que par exemple un objet
implémenté par un hash n'hérite pas de la classe HASH, alors que
son code en aurait besoin (son code appelle différentes méthodes
suivant le type d'un paramètre de la méthode). Sa solution est de
surcharger bless() ! Ainsi il recupère le type de l'objet et
le pousse dans @ISA, ce qui fait que la classe en hérite.
Il utilise
pour remplacer le bless() de Perl par le sien. Cela ne marche
toutefois qu'avec un Perl récent, 5.8 ou peut-être 5.6, il ne sait
pas.
Puis il utilise AUTOLOAD() pour éviter de bless-er les classes
qu'il ne faut pas blesser et rajoute un petit bout de code qui fait
que tous les types de bases héritent d'un type unique (je n'ai pas
tout compris le pourquoi à vrai dire).
À la fin de son talk, Piers avoue qu'il a eu l'idée et a écrit le code le matin-même et promet que le module atterrira bientôt sur le CPAN.
Robin nous expose dans ce talk l'intérêt d'utiliser l'API SAX par rapport à DOM.
Il commence en expliquant que, bien que DOM et SAX soient toutes deux des API basées sur des arbres, leur implémentation est assez différentes et conduit à des consommations mémoire très différentes. En particulier, SAX est plus économe que DOM dont la plupart des implémentations chargent tout le document XML en mémoire.
Il oppose ainsi les API push (comme SAX) aux API pull (présentes dans le framework .NET de Microsoft) en indiquant que le contrôle que le programmeur croit conserver par l'utilisation d'une API pull (où le programmeur va extraire les données) est une illusion.
Dans le cas d'une API push, les données sont fournies au programme au fur et à mesure de la lecture du document XML, qui ne voit donc ces données que par fragments. On parle alors plutôt de filtre. L'intérêt est qu'on peut alors facilement chaîner plusieurs filtres les uns à la suite des autres, comme on peut chaîner des commandes Unix dans un tube.
Le gros avantage de cette programmation événementielle est qu'un filtre est plus facile à écrire car on peut ne conserver que la partie qui nous intéresse, en laissant passer le reste. Reste qui pourra être traité par le filtre suivant.
Robin présente ensuite XML::SAX::ParserFactory qui permet
de sélectionner automatiquement le « meilleur » parser SAX
disponible sur le système, avec en dernier recours un parser
en pur Perl. Pour comparer, c'est un peu comme si on pouvait
faire du DBI sans devoir indiquer le driver de base de données.
Il présente enfin XML::SAX::Machines, qui est un module
comprenant quelques filtres bien utiles comme les étonnants
XML::Filter::Tee et XML::Filter::Merger qui permettent
respectivement d'envoyer des événements SAX à plusieurs
processeurs et de fusionner plusieurs flux SAX en un seul !
Merci à Robin Berjon pour avoir corrigé mes erreurs concernant les API.
Michel va tenter de débroussailler un peu la jungle des modules
XML présents sur le CPAN, près de 150 vivants actuellement dans
l'espace XML::*.
Après avoir présenté quelques critères afin de s'y retrouver, il explique les acronymes les plus courants du monde XML (qui en compte beaucoup) et profite de l'occasion (et de l'absence de Robin Berjon) pour dire du mal de SAX.
Il montre ensuite une carte des modules XML majeurs. On remarque
que certains modules (XML::Parser, XML::DOM) sont en rouge
pour signaler qu'ils ne devraient jamais être utilisés directement.
Michel présente ensuite la différence entre le XML « orienté document » et le XML « orienté données ». Pour faire simple, le premier ressemble à du XHTML, le second à de la bouillie de tags (typiquement ce qui est utilisé comme format pour les fichiers de configuration par les projets Jakarta). Mais Michel présente au contraire des arguments pour expliquer que la seconde forme est préférable car elle est fortement structurée, ce qui simplifie le travail. Autre argument, cela constituerait selon lui la majorité des données XML à ce jour.
Il rappelle qu'il est toujours en train d'écrire la nouvelle version de Ways to Rome, puis présente un exemple basé sur le format des factures de la Finnish Bankers Association.
Michel présente les différentes manières de gérer son XML : charger tout le document dans des structures Perl ou dans un arbre et ne plus se soucier du XML, ou le traiter en flux avec des filtres SAX. Il rappelle aussi qu'un document XML se doit d'être valide et qu'il faut se soucier de son encodage.
Uri annonce que son talk consiste principalement en un ensemble de règles de bon sens de développement, qui sont trop souvent ignorées.
Le code doit être écrit pour le mainteneur, car c'est le mainteneur
(que ce soit soi-même ou une autre personne) qui devra relire le
code six mois plus tard pour corriger d'éventuels bugs ou ajouter
des fonctionnalités. En conséquence, Uri recommande de nommer
les choses (variables, fonctions, objets, etc) de manière appropriée,
de sorte que ce soit compréhensible. Éviter donc les $foo,
@bar et autres $pipo{$machin}.
Il donne aussi le conseil suivant sur les commentaires : les commentaires doivent indiquer pourquoi le code fait telle ou telle chose. Écrire
est inutile et ne sert à rien, si ce n'est à ajouter du bruit.
Il indique aussi que programmer du code spaghetti aboutit à la confusion et recommande donc de programmer du code lasagnes ! En effet le code est organisé en couches réalisant des fonctionnalités spécifiques et communiquant par des interfaces.
En résumé (qui devrait être accroché au-dessus du poste de chaque développeur, quel que que soit son langage) :
Code is for People, not for Computers
Code is for Others, not for Yourself
Code is What, Comments are Why
Uri présente ensuite quelques exemples autour des contextes
d'exécution. Il fait un rappel sur wantarray() et montre
qu'outre les contextes scalaire et de liste, elle renvoie aussi
undef en contexte vide. Il conseille d'utiliser Want.pm, qui
offre plus de possibilité que wantarray().
Il y a aussi toute une discussion autour de l'utilisation des here-documents. Uri essaye de convaincre quelqu'un dans le public qui pense du mal des here-documents que, oui, les here-documents c'est bien. L'argumentation porte en particulier sur les problèmes d'indentation que cela implique.
mock commence par expliquer que Net::SSLeay n'est pas vraiment sûr
parce qu'il ne vérifie pas vraiment l'authenticité du certificat
de la machine avec laquelle il cause.
Il montre ensuite un exemple de code qui lui permet de trafiquer
l'adresse source avec LWP. En gros il ré-écrit les
paquets comme il veut. Ca semble bien evil comme manipulation.
Il faut dire qu'il bosse pour une boîte (dont il ne peut pas dire
le nom) qui fait dans l'e-commerce de trucs pas vraiment illégaux,
mais pas complètement légaux non plus, en tout cas pas légaux
partout.
SourceIP sera bientôt sur le CPAN, et il prévoit d'écrire une
pile TCP/IP en Perl pour pouvoir en faire encore plus.
Le but de la manipulation est de feinter Google en lui faisant croire qu'une machine est vraiment plusieurs machines. Ca lui permet aussi de truquer les sondages en ligne (les programmes de ce genre sont souvent basés sur le principe de une adresse IP = un vote).
Matt Sergeant n'est pas trop content, c'est le côté obscur de la force !
Peter présente d'abord File::Scan, un module qui permet de scanner
les fichiers et d'y détecter d'éventuels virus. Selon lui, le module
est sympathique mais insuffisant en production puisque les signatures
de virus ne sont disponibles qu'une ou deux semaines après la
publication de ces signatures chez les éditeurs commerciaux. Et
évidemment il ne dispose pas d'un support commercial.
Il présente ensuite SAVI qui est un module s'interfaçant avec le
logiciel Sophos Antivirus via la bibliothèque libsavi. L'intérêt
est que Sophos est disponible gratuitement en version d'évaluation
pour une large variété de systèmes (Windows, Unix, Linux, Mac,
VMS, etc). Si on achète la version complète on dispose alors d'un
support commercial. (On peut noter que courant 2003, Sophos a racheté
ActiveState, le principal éditeur de Perl pour Windows.)
Il explique ensuite les méthodes de base pour écrire son propre anti-virus pour emails en exposant les principaux mécanismes de fonctionnement de ces virus. En effet les virus de mails sont pour la plupart basés sur l'exploitation de failles dans les logiciels. Bien que les virus doivent créer de toute pièce des mails ayant l'air valides, ils contiennent nécessairement l'exploit en clair dans le corps de l'email, qu'on peut donc intercepter grâce à Perl.
À vrai dire ce talk était un peu décevant car il a juste présenté des techniques assez générales, connues depuis longtemps et sans montrer d'exemple en Perl.
Marty nous présente en trois slides une méthodologie de
développement basée sur le système suivant : avant d'écrire
le code, quand on sait ce qu'il doit faire, on écrit les tests
correspondants, seulement ensuite on écrit effectivement le
code et on exécute make test à la fin pour vérifier que cela fonctionne.
Le principe est donc que les tests constituent le design fonctionnel
du code. L'écriture du programme est terminée quand tous les
tests réussissent.
Marra nous montre un joli site web qui génère des statistiques pour des universités, à partir d'une base de données, en générant des graphiques à la volée, le tout piloté par quelques fichiers de configuration rusés (pas en XML !). Son système est sympathique, facile à configurer pour de nouvelles applications, et assez joli. Ce n'est pas un logiciel ouvert, mais principalement parce qu'elle n'a pas eu le temps de nettoyer le tout et d'en faire une distribution propre. Elle espère le faire cet été.
Jo discute de RDF, de coordonnées spatiales et parle de « mapper » le monde cybernétique sur le monde réel.
mudlondon est une représentation de Londres dont l'interface
purement textuelle est empruntée aux jeux de MUD (Multi-User Donjon).
C'est un robot
avec lequel on communique via Jabber. Les lieux réels sont
modélisés comme des nœuds de graphes, ces nœuds pouvant être
annotés, y compris en utilisant FOAF (Friends of a Friend),
ou des photos, des URLs, etc. Le tout est en RDF (puisque c'est
à la mode et qu'il y a pas mal de logiciels qui le gèrent).
On peut bien sûr rajouter une dimension temporelle, ce qui permet d'établir le chemin parcouru par quelqu'un par exemple. Un slide décrit le processus de manière intéressante : la big picture est construite à partir des images mentales de plusieurs individus.
Jo montre aussi comment employer SVG pour visualiser les cartes décrites en RDF. Elle indique le site de carto:net. Elle note qu'il y a toutefois des problèmes de copyright : les données cartographiques au Royaume-Uni sont propriété de la Couronne (et licenciées).
Oops ! Elle emploie le mot « ontologie », je décroche officiellement ! Sérieusement, en fait c'est pas mal ces trucs, c'est plus l'aspect utilisation de la technologie pour faire des trucs socialement intéressant. Ca fait réflechir.
Dans ce talk Philip nous expose un cas d'utilisation de Perl comme simulateur de RFC 1086.
Il explique d'abord ce que c'est : une passerelle TCP/IP - X.25. Sa boîte avait un logiciel en C++ qui marchait au-dessus de X.25 et qui envisageait d'utiliser un système de ce genre. Pour tester quels changements il aurait à effectuer dans le code C++, il a décidé d'écrire ce simulateur.
La difficulté résidait dans le fait qu'il devait gérer trois connexions simultanément.
![[schéma]](yapc2003/tcpip-x25.png "schéma d'une passerelle TCP/IP - X.25")
Il a alors décidé d'utiliser les threads de Perl 5.6, et présente quelques-unes des fonctionnalités offertes par Perl.
Il montre d'abord comment on peut partager des données (ici
des variables) entre threads grâce à threads::shared :
Il explique ensuite comment créer une queue thread-safe avec
Thread::Queue : on peut ainsi ajouter des données dans cette
queue depuis un thread et en lire depuis un autre :
Il montre enfin comment créer un sémaphore avec Thread::Semaphore.
Il conclut en expliquant que son simulateur n'a servi à rien car sa boîte a finalement décidé d'utiliser une autre solution, mais il était content car il avait pu découvrir les threads en Perl.
Bon, j'avoue je suis là parce que le titre me fait rire.
Il semble qu'il veuille parler de l'impact social de notre boulot
de programmeur. Apparemment on n'est pas assez sensibilisé a ça
(il ne lit visiblement pas SlashDot ;-)
Yipee ! Une citation en latin : mors tua vita mea, ta mort est ma vie (référence au principe fondamental de la chaîne alimentaire). Ca ne s'applique bien sûr qu'à des objets physiques. Zut, j'ai raté la citation qui s'applique à des créations de l'esprit.
Bon, maintenant il nous explique ce que sont les meta-données, en commençant par dire que les commentaires du code sont des meta-données. Hummm, je suis pas sûr là... Puis un menu de restaurant, d'abord en version texte, puis en version XML.
Les meta-données nous aident à tirer le meilleur parti de nos données. Les utilisateurs devraient les utiliser de manière transparente.
Autant la présentation précedente (Mapping the wireless revolution on the semantic web) semblait touffue et barge au départ, mais prenait du sens petit à petit, autant celle-ci me semble habiller de grands mots des concepts plutôt simples. Tiens, voici le mot « paradigme » d'ailleurs !
Il donne un conseil utile : les programmeurs devraient écrire du code propre ! Incroyable ! Un autre : évitez Python (rires).
Il râle, on devrait dire Free Software et pas OSS. Personnellement, je suis très content que la licence de Perl soit l'Artistic License, le nom et son contenu me conviennent très bien !
Il saute prudemment le slide où il explique que les fichiers de configuration devraient être en XML (le sujet d'une partie de mon talk du matin, où je poussais YAML à la place).
On finit par une nouvelle citation latine : vita tua vita mea, ta vie est ma vie.
Ces deux citations latines et l'orientation du talk qui se veut social nous mettent sur la piste de textes qui présentent des voies alternatives au capitalisme, très fouriéristes. Sans que ce soit nécessairement une mauvaise idée, cette présentation tombe dans un technochamanisme sans grand intérêt.
Ce talk est destiné à nous présenter le module Devel::Cover,
dont le but est de déterminer de manière pratique la couverture
de code.
La couverture d'un code est la partie du code qui est exécutée
au cours d'un ensemble d'instances d'exécution. En clair, ce
module permet de vérifier si le code contient des parties mortes
ainsi que de vérifier quelles sont les parties les plus exécutées
(utile pour déterminer lesquelles sont à optimiser).
Cela ressemble donc un peu à Devel::DProf mais en utilisant
un système de profilage différent (basé sur la surcharge des ops
de l'interpréteur Perl) et surtout en fournissant en sortie un
rapport en HTML permettant de suivre l'exécution du code par
ligne, par branche et par boucle.
L'utilisation de Devel::Cover est aussi simple que ça :
$ perl -MDevel::Cover program.pl
$ cover -report html
Un aspect regrettable est que Paul a tendance à traîner en longueur
sur son exemple alors que plusieurs personnes (dont moi-même et
Arnaud) trépignent d'impatience en se demandant s'il va montrer
le Makefile.PL permettant de lancer un make test avec
Devel::Cover (ce qui constitue une technique fabuleuse pour
vérifier que les tests font s'exécuter tout ou partie du code).
Il s'excuse en disant qu'on lui avait déjà posé la question à
Munich, qu'il n'avait pas pu la fournir et que là il avait oublié
ce qu'il fallait ajouter à Makefile.PL pour avoir make cover.
En fait, pour utiliser Devel::Cover en conjonction avec
Test::Harness, il faut exécuter :
$ cover -delete
$ HARNESS_PERL_SWITCHES=-MDevel::Cover make test
$ cover -report html
Il parle ensuite de CPAN Cover, un projet dérivé qui consiste
à exécuter un make cover sur tous les modules du CPAN.
http://homepage.hispeed.ch/pjcj/testing_and_code_coverage/index.html
Devel::Cover
Dmitri commence par présenter PRIMA, un toolkit graphique Perl qui fonctionne sous Unix/X11, Win32 et OS/2 dédié à la manipulation graphique. Il propose ainsi la conversion entre différents formats, supporte Unicode et utilise PostScript pour l'impression. Est aussi inclus un outil de création graphique, Visual Builder, écrit en Perl et qui génère du code Perl.
Dmitri montre un exemple où il crée un bouton. Quand il le tourne, un bout de texte tourne en même temps. Shiny ! Il nous montre maintenant un bout de code qui balance des nombres à la Matrix à travers l'écran. Joli !
Puis la présentation continue avec la démonstration de la bibliothèque de manipulation d'images IPA (Image Processing Algorithms). Ils s'appuient sur PDL (Perl Data Language) pour l'implémentation des algorithmes.
Enfin un talk qui s'annonce pratique et utile !
Oh non, premier slide et déjà le mot metadata vient polluer la
présentation ;-(
Paul commence d'abord par un rappel sur ce qu'est ID3 (le standard de... méta-données pour les fichiers audio MPEG). Il explique les différences entre ID3v1 et ID3v2. La version 1 était très simple, ce n'était qu'un simple hack du format MPEG composé de 7 champs fixes, la plupart d'environ 30 caractères de long. La version 2 est beaucoup plus compliquée. ID3v2 est aussi assez compliqué à écrire.
Il présente trois modules qui peuvent traiter les champs ID3 :
MP3::Info de Chris Nandor est un module pur Perl, qui peut
lire les tags ID3v1 et v2, mais ne sait écrire que du v1.
MP3::Tag de Thomas Geffert est aussi un module pur Perl
mais qui est capable de lire et d'écrire les tags au deux
formats (jusqu'à ID3v2.3). Son utilisation n'est toutefois
pas la même suivant si on édite des tags au format v1 ou v2.
MP3::ID3Lib de Leon Brocard s'appuie sur la bibliothèque C
ID3Lib pour lire et écrire les tags au format v1 et v2. La
manipulation des tags passe dans tous les cas par les labels
ID3v2.
Un truc qu'on doit souvent faire, c'est générer les tags ID3. Il nous montre un script Perl qui le fait. Je ne comprends pas d'où il récupère l'info. Du nom de fichier il semble. En sens inverse, on veut souvent renommer le fichier d'après les tags ID3. Et voili, un script le fait. Un autre qui met les bons tags pour les morceaux tirés de compilations.
Pour les cas où on a pas vraiment le CD sous la main, il existe
deux projets open source : FreeDB (simple, clone de CDDB) et
MusicBrainz (plus ambitieux, offre des données RDF, des Web
Services, etc). Et évidemment on dispose de modules Perl
appropriés : Webservices::FreeDB (probablement fragile car
fait du screen scrapping), et Music::Brainz::Client basé sur
une bibliothèque C, peut récupérer les données en RDF. D'après
lui assez difficile à utiliser.
La présentation des divers modules est pas mal, ça donne une bonne idée de l'ensemble.
Pour certaines raisons, ce talk a attiré beaucoup de personnes qui, venant en avance, ont débarqué dans celui de Guillaume Rousse, Yet another Perl biology toolkit. Désolé Guillaume.
Jos a en effet présenté vingt modules (ou pseudo-modules) en prenant comme thème de présentation le Seigneur des Anneaux :
Neuf furent donnés aux Hommes mortels,
Sept aux Nains avides d'or,
Trois furent protégés par les Elfes,
Et l'Unique, le Maître Anneau, forgé par Sauron.
Les modules n'ont en réalité pas grand-chose à voir avec les Elfes ou les Anneaux, mais l'idée est amusante et surtout Jos était un bon orateur.
Sur tous les modules qu'il a présenté au pas de charge (20 modules en 20 minutes, cela ne fait qu'une minute par module !), je n'en ai retenu que quelques-uns :
Devel::Peek qui permet de voir les structures internes de
l'interpréteur Perl ;
File::Chdir qui permet de gérer automatiquement le répertoire
courant ;
Config::Auto, un module de gestion de fichiers de configuration ;
Hook::Scope qui permet d'avoir l'équivalent de BEGIN et END
mais au niveau scope (c'est-à-dire au niveau des blocs) ;
Hook::LexWrap, un module de Damian Conway qui fait quelque
chose de similaire mais au niveau des fonctions si j'ai bien compris ;
Scalar::Utils qui permet de stocker plusieurs valeurs différentes
(un entier ET une chaîne) dans une même variable ;
Dans ce talk aussi Nicholas Clark a réussi à parler de Acme::Buffy
:-)
Traditionnellement, c'est à la fin d'une présentation que l'orateur demande s'il y a des questions. Dans ce cas-ci, Tim a préféré laissé le public lui poser toutes les questions sur ce module central de la programmation des bases de données en Perl. Et Tim d'y répondre à chaque fois avec précision et concision, forçant l'admiration de son public.
C'est un Dan Sugalski complètement fracassé par le voyage en avion qui nous présente Parrot en commençant par expliquer en quoi l'interpréteur Perl5 actuel est un vrai merdier. En effet, Perl5 est le résultat de 9 ans de patches successifs pour ajouter un ensemble de fonctionnalités qui n'avaient pas été prévues au départ car cela n'existait pas à l'époque : on pense tout particulièrement au support des threads et d'Unicode.
Des tas de personnes ont donc proposé des patches en disant que « cela ne coûte qu'1% du temps d'exécution ». Mais les patches étant acceptés, les pourcentages se sont additionnés pour ralentir de manière sensible l'interpréteur Perl. (Raison pour laquelle Nicholas Clark indiquait qu'un moyen potentiel d'accélérer un programme était d'utiliser une ancienne version de Perl.)
Perl6 se base sur une machine virtuelle (VM) totalement nouvelle, Parrot. Cette machine virtuelle a été conçue en utilisant les dernières avancées en matière des techniques de VM et des théories de compilation et de conception des CPU (ces domaines étant très liés). Le projet est ambitieux mais on espère ainsi que cette VM évoluera de manière plus douce sur la décennie à venir.
L'autre ambition de Parrot est que cette VM soit suffisamment générique pour servir de base d'exécution à d'autres langages comme Ruby ou Python.
Dan expose ensuite la véritable raison qui l'a décidé à programmer Parrot : jouer à Zork nativement. (Zork était un jeu d'aventures en mode texte).
En effet, Parrot offrira nativement bon nombre de fonctionnalités très intéressantes comme le support de bytecode portable (semblable à Java ou Python) et un garbage collector (GC) natif de bien meilleur qualité que celui de Perl5 (le GC de Parrot sera de type mark and sweep, comme celui de Lisp).
Ce qui nous amène à un point essentiel dans le développement de Parrot : le défi que Guido von Rossum a lancé à Dan Sugalski, à savoir que selon Guido, Parrot ne sera pas capable d'exécuter Python plus rapidement que CPython (l'interpréteur Python écrit en C) d'ici le prochain OScon (qui aura lieu fin juillet 2004). L'enjeu est le lancer de tarte à la crème à la figure du perdant, d'où l'orthographe spéciale de Python durant tous ces talks, « Pie-thon ».
Dan a expliqué qu'il a toutes les chances de se trouver du bon côté de la tarte car Parrot est ou sera bientôt capable de charger n'importe quel type de bytecode : Python, Zork et même Java !
Dans un anglais quelque peu hésitant, Leo nous explique les bases de la programmation en Parrot. En plus de l'aspect très technique mais néanmoins intéressant de cette présentation, ce talk a attiré pas mal de monde car il s'agissait de la première apparition publique de Leo. On a ainsi pu constater qu'il existe réellement et qu'il n'est bien qu'une seule personne.
Leo nous apprend qu'on peut d'ores et déjà programmer en PIR,
Parrot Intermediate Representation Language, qui est un genre
de macro-assembleur à base de registres typés avec support des
espaces de noms. Ce langage est ensuite traduit par IMCC en
PASM, l'assembleur Parrot, qui est ensuite compilé en PBC,
Parrot Bytecode. Ce dernier est chargé par la VM par mmap()
(une fonction de chargement de fichier rapide) et après
quelques transformations (comme la gestion de l'endianness),
le code est exécuté.
Leo présente ensuite quelques points qui permettent à Parrot d'être très rapide :
Parrot est une machine à registres, c'est-à-dire que tant la VM que le langage d'assembleur considèrent qu'on a beaucoup de registres disponibles, ce qui simplifie la vie du programmeur et est facile à optimiser en aval (par aliasing de registres par exemple). La VM ressemble donc à un processeur RISC (genre PowerPC ou Sparc).
Les PMC (Parrot Magic Cookies) ont une taille de 32 octets.
Là je dois reconnaître qu'il m'a un peu embrouillé dans ses explications et je ne pas trop compris ses arguments, mais une comparaison avec les vrais CPUs indique qu'une taille fixe égale à un multiple entier de mots machine permet de se simplifier la vie lors des calculs d'adresses (là encore voir l'opposition entre les CPU RISC et x86). Cela permettrait aussi plusieurs optimisations pour la DOD et le GC.
DOD (Dead Object Detection).
COW (Copy-on-Write) est un mécanisme qui permet de retarder les opérations d'allocations mémoire au plus tard. L'exemple typique est :
Habituellement, le contenu de $foo est copié dans un nouvel
espace mémoire qui sera pointé par $bar. Avec COW, $bar
pointe vers l'espace mémoire de $foo, et ce n'est que si on
modifie la valeur de l'une ou l'autre des variables qu'un
nouvel espace mémoire est créé. Ce mécanisme fonctionne pour
tous les types d'objets natifs car c'est nécessaire pour la
gestion des continuations.
Cette fonctionnalité semblait particulièrement intéresser certaines personnes du public qui avaient posé la question à MJD lors de son talk Tricks of the Wizard. Le mécanisme sera par la suite mis en scène par Nicholas Clark lors de son lightning talk.
Leo expose ensuite quelques uns des différents run cores disponibles dans Parrot. Si j'ai bien compris, les run cores sont les cœurs d'exécution de Parrot, mais comme ils n'étaient pas sûr de savoir quel mécanisme serait le plus efficace, ils ont développé plusieurs run cores : Fast Core, Goto Core, Slow Core, et des combinaisons. Leo montre le cœur du Fast Core avec cet extrait de code C :
while(PC) {
PC = ((INTERP->op_func_table)[*PC])(PC,INTERP);
}
Un ange passe et semble aussi dubitatif que le public face à ça.
Leo explique ensuite que Parrot dispose d'un sous-système JIT (Just-In-Time) disponible pour plusieurs architectures (x86, PowerPC, Sparc, ARM, Alpha).
Pour rappel, un système JIT (aussi dit de recompilation dynamique), permet de transformer le bytecode en code natif pour le CPU de la machine hôte. C'est ce qui permet à Java d'avoir des vitesses d'exécution à peu près acceptables.
Leo nous montre le résultat d'un benchmark qu'il avait lancé au cours de son talk ; c'est un truc calculatoire écrit en Perl et en Python. Les temps d'exécution sont lamentables, à peine 2 ops par seconde en Perl et 1 op par seconde en Python. « Times are rounded up ! » précise Leo. Il exécute le même en Parrot : quelques secondes, soit presque 800 ops par secondes (son PowerBook tourne à 800 MHz..)
Après cette démonstration, Leo conclut sur le système JIT en indiquant que comme on a pu le constater, on peut arriver à exécuter jusqu'à une instruction Parrot par cycle CPU ! Évidemment, c'est surtout valable pour les instructions « simples » (ou du moins disponibles dans le CPU), mais c'est néanmoins assez impressionnant.
Sa présentation terminée, quelqu'un dans le public demande à Leo de montrer ce qu'il utilise pour ses « slides » (du texte affiché dans un terminal qui efface l'écran et défile quand il appuie sur une touche) : « Parrot of course ! ». Il montre le code PIR qu'il a utilisé pour son talk, qui doit faire moins d'une cinquantaine de lignes. Nouvelle salve d'applaudissements.
Merci à Stéphane Payrard pour ses corrections et précisions.
Le talk de Leon est consacré aux petits langages déjà disponibles au-dessus de Parrot.
Il commence par expliquer ce qu'il entend par « petit langage ». Sa définition est que c'est un langage spécialisé pour une tâche donnée dont la syntaxe est compacte jusqu'à la rendre complètement hermétique pour qui ne parle pas ce langage. En clair, un petit langage est insane.
Il donne des exemples pour montrer qu'on est entourés de petits langages : regexp, awk, sed, bc, nroff, pic...
Il parle ensuite des langages qui ont été implémentés au-dessus de Parrot.
BrainFuck : il en parle un peu, montre un ou deux exemples mais n'insiste pas trop (peut-être pour faire oublier qu'il est le responsable de l'interpréteur BF).
Befunge : il explique que c'est un langage très particulier car
il est basé sur un espace de @$#%?&*!! ce qui en fait donc un
langage bidimensionnel (j'ai pas retenu les noms mais on aurait
aussi bien pu me dire que c'était un espace pré-hilbertien, pour
moi c'est juste un espace à topologie torique ; Jérôme Quelin me
précisera par la suite que c'est un espace cartésien de Lahey à
deux dimensions). Les instructions sont des instructions de
directions qui indiquent où on doit aller pour continuer
l'exécution. Leon montre un exemple et explique à l'assemblée
comment il s'exécute. Le public est mort de rire et Leon lui-même
a du mal à garder contenance :-D
Quelqu'un demande si on peut exécuter deux instances sur un même « source » pour faire un bot-war. Leon répond que non car c'est compliqué mais pas impossible. Il précise que Jérôme Quelin est le responsable de l'implémentation de ce langage sur Parrot.
BASIC : car oui, Parrot est capable d'exécuter le GW-BASIC et le QuickBASIC 4.5 de Microsoft. Leon ne montre pas d'exemple mais assure que ça marche. (D'un autre côté ça plomberait son talk car BASIC constitue le premier « vrai » langage porté au-dessus de Parrot.)
Lua, qui est un autre langage de script.
Marty commence par nous dire 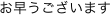 [ohayô gozaimasu], c'est-à-dire « bonjour »
[ohayô gozaimasu], c'est-à-dire « bonjour » ^_^
Le titre de son talk est  . Par bonté d'âme il nous donne l'écriture en
kana
. Par bonté d'âme il nous donne l'écriture en
kana 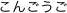 [kongôgo]
et explique le sens
de ce mot : il désigne la création d'un nouveau langage par
mélange et contamination de deux ou plusieurs autres langages.
Selon lui, c'est l'idée fondamentale derrière Perl6.
[kongôgo]
et explique le sens
de ce mot : il désigne la création d'un nouveau langage par
mélange et contamination de deux ou plusieurs autres langages.
Selon lui, c'est l'idée fondamentale derrière Perl6.
Il explique que Matz (diminutif de Yukihiro Matsumoto) voulait créer le meilleur langage de programmation. Il a donc volé un grand nombre de fonctionnalités à Perl afin d'écrire Ruby.
Marty insiste (comme avant lui Dan Sugalski) sur le fait que Perl6 a démarré dans le but de contrecarrer la concurrence que Ruby risquait de faire à Perl. Larry a d'ailleurs déclaré à plusieurs reprises l'admiration qu'il a envers Ruby. Mais cette admiration ne l'a pas empêché de chercher un moyen de renouveler Perl afin qu'il reste supérieur à Ruby (et évidemment à Python).
La première solution a été de voler à Ruby les fonctionnalités qui risquait d'attirer les programmeurs :
-> s'écrit maintenant .
toute chose est un objet
support des coroutines et des continuations
Mais cela signifiait malgré tout rester derrière Ruby en terme d'innovation, ce qui aurait été insuffisant. Larry a donc décidé de voler les « fonctionnalités » de la langue maternelle de Matz, le japonais, grâce à ses talents de linguiste.
Marty commence alors à étayer sa théorie en montrant que Larry a commencé à apprendre le japonais il y a deux ans, peu de temps avant de lancer le projet Perl6. On sait aussi que Larry a fait quelques voyages au Japon et qu'il chante la musique de Totoro ! Par ailleurs Simon Cozens parle couramment japonais et Marty ajoute que plusieurs hackers de Perl6 sont en train d'apprendre le japonais ou du moins s'y intéressent de près.
Il apporte comme preuve le fait qu'on puisse dès maintenant écrire du Perl en japonais dans le source (depuis 5.8 et le support d'Unicode) :
![[code d'exemple]](yapc2003/example_code.png "exemple de code Perl écrit en japonais")
Vous aurez reconnu (!) le code :
Perl5 et le japonais avaient déjà en commun la concision et les multiples manières de faire ou dire les choses. Marty nous montre six manières différentes de dire aller (ç'aurait pu être pire, il aurait pu nous citer les 28 manières différentes de dire « je »).
Il essaie ensuite de nous présenter les fonctionnalités du japonais que Larry a décidé de reprendre pour Perl6 comme l'utilisation intensive du contexte. Pour nous convaincre il fait répéter à la salle des phrases en japonais : « les deux canards sont dans le jardin », puis « le crocodile a mangé les deux canards dans le jardin ».
Marty nous explique ainsi que le japonais a ceci de particulier
qu'il fait une grande utilisation du contexte courant du
dialogue, ce qui permet d'éviter beaucoup de mots redondants
(comme les pronoms, les articles, les locutions). Perl6
étend la notion de contexte déjà présente dans Perl5 (avec
$_) avec le mot-clé given, un peu à
la manière du 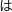 [wa]
en japonais : on marque une partie d'une phrase
comme le topic, le sujet de la discussion, et on n'a plus
besoin de le répéter après.
[wa]
en japonais : on marque une partie d'une phrase
comme le topic, le sujet de la discussion, et on n'a plus
besoin de le répéter après.
Il rappelle aussi que les japonais sont très friands
d'abréviations formées en ne conservant que deux ou trois
syllabes d'une expression. Par exemple, au lieu de perdre
du temps à parler de word processor, un japonais dira
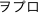 [wopro].
(Autres exemples, le nom de la société de
jeux Sega vient de Service Game, et celui du célèbre Comiket
de Comics Market.)
[wopro].
(Autres exemples, le nom de la société de
jeux Sega vient de Service Game, et celui du célèbre Comiket
de Comics Market.)
Puis il nous raconte quelques anecdotes de son périple en tant
que  [gaijin]
au Japon où il s'est laissé abusé par cette
notion de contexte si particulière.
[gaijin]
au Japon où il s'est laissé abusé par cette
notion de contexte si particulière.
Enfin il conclut en nous recommandant de faire une recherche sur le web sur « Larry Wall » et « Japanese » et de prendre peur. Peut-être fait-il allusion à l'un des articles suivants ?
Laissant la salle interrogative, il termine par  [arigatô gosaimasu], « merci beaucoup ».
[arigatô gosaimasu], « merci beaucoup ».
http://joi.ito.com/archives/2002/09/10/larry_wall_on_god.html
http://interviews.slashdot.org/article.pl?sid=02/09/06/1343222
Ann explique pourquoi son diplôme en histoire, écriture et philosophie l'a bien préparée a la vie professionelle. C'est plutôt rigolo.
Dan expose l'état actuel de Parrot, ce qui marche, ce qui ne marche pas. Il est globalement content même si plusieurs parties restent encore en chantier (l'implémentation actuelle de Parrot est thread-safe mais la gestion des threads est à écrire) et il reste de toute façon motivé pour avancer rapidement car 1) il veut jouer à Zork, 2) il veut lancer la tarte sur Guido (et pas l'inverse) !
Porn0graph utilise RDF pour modéliser les relations entre plusieurs morceaux d'histoire. On génère des histoires complètes en traversant le graphe RDF et en prenant des chemins au hasard (ou en laissant l'utilisateur choisir) quand il y en a plusieurs.
C'est écrit avec POE, et utilise du HTTP normal (requêtes
GET et POST). « None of this WSDL, SOAP, XML-RPC non-sense »
;-). Les triplets RDF sont stockés dans
une base de données MySQL. Le langage de requête sur RDF est
Squish, et est traduit en SQL. Il y a des interfaces Jabber
(onanova), HTML et dans le futur SVG. On peut aussi donner
des ordres comme dans un jeu d'aventure (genre use whip).
Une autre évolution possible est de lier ce moteur à des ontologies (si je me rappelle bien, une ontologie c'est une catégorisation d'un sujet, mettre des noms sur des concepts et décrire leurs relations). Elle nous montre un graphe qui décrit les fétiches typiques et leurs relations.
Ce talk très intéressant cachait néanmoins une grosse
déception : aucune démonstration ! ;-)
En (très) résumé : le CPAN, c'est bien, mais pensez à
mettre un numéro de version (avec $VERSION).
Arthur explique que la société Fotango (pour laquelle il travaille) a donné son accord à ses développeurs pour commencer le portage de Perl5 sur Parrot afin d'assurer une meilleure transition pour le passage de Perl5 à Perl6. Le nom du projet est Ponie, l'acronyme de Perl On a New Internal Engine.
Le principe est de toucher le moins possible au code actuel de Perl5. Les lexer, parser, tokenizer et moteur de regexp en particulier ne seront pas modifiés. Seul le cœur doit être transformé pour s'interfacer avec Parrot.
Les variables, ainsi que certains opcodes, seront implémentés
par des PMCs (Parrot Magic Cookies), ce qui devrait permettre
à tout le code XS de fonctionner. Cela devrait même améliorer
la vitesse d'exécution de certains mécanismes traditionnellement
lents comme la surcharge (overloading) et tie().
Les grosses difficultés sont aussi déjà connues : Perl5 utilise toujours son GC basé sur le comptage de référence alors que Parrot possède un GC bien plus efficace de type mark and sweep (marquage et effacement) ; de même, Perl5 et Parrot ont chacun leur système de gestion de l'Unicode.
Arthur pense par contre que les threads devraient poser moins de problèmes.
Il espère fournir un premier prototype dans les huit mois et obtenir quelque chose de solide d'ici deux ans.
Greg nous explique pourquoi il n'a pas voulu faire de talk cette année : il faut choisir un sujet, ce qui est compliqué. Résultat il n'arrive pas à se décider de quoi parler, et si jamais il sait de quoi parler il doit alors préparer le talk mais comme ça le stresse il n'arrive pas à se concentrer et doit quitter son ordinateur, ce qui l'empêche de faire des trucs amusants. C'est donc la raison pour laquelle il a décidé de ne pas faire de talk, afin de rester sur son ordinateur à découvrir des trucs amusants et nous livre ainsi en vrac les résultats de ses découvertes.
Jabber - Il aime bien Jabber car il peut s'envoyer des messages instantanés ou des messages à durée de vie plus longue pour savoir s'il a du mail ou monitorer d'autres trucs.
CVS - Il a découvert qu'on pouvait ajouter des trucs dans un serveur CVS pour qu'il envoie des mails automatiquement quand quelqu'un committe quelque chose, et a découvert encore mieux : comment envoyer des messages Jabber lors d'un commit ; ainsi sa boîte aux lettres n'est pas remplie de mails dont il n'a que faire mais il est quand même averti quand quelqu'un a touché au code pendant qu'il s'est absenté.
Il parle encore de quelques autres trucs puis on lui annonce que son temps est écoulé et il est surpris d'avoir déjà terminé son talk qui n'en était pas un car il avait encore plein de choses à dire.
Pendant que la salle se remplit au fur et à mesure, MJD se prépare à diriger les lightning talks. Il déballe d'abord un chronomètre et une petite sonnette, puis ouvre un grand carton d'où il sort son célèbre gong.
Nick décide de nous expliquer de manière très visuelle comment
fonctionne le Copy-on-Write avec l'aide de quelques londoniens
donc Leon Brocard, chacun représentant une variable scalaire.
Nick débute avec Leon qui pointe vers une valeur de chaîne
(imprimée sur une feuille qu'il déplie), « Buffy » (ce qui ne
surprend personne :-)). Puis il montre ce qui se passe quand
d'autres variables pointent vers cette chaîne, et quand certaines
d'entre elles sont modifiées.
Jonas montre comment construire une petite calculette en utilisant CamelBones.
CamelBones, développé par Sherm Pendley, est un pont entre Perl et Objective-C permettant de construire des applications Cocoa (l'API graphique et applicative de Mac OS X). Après une rapide présentation de CamelBones, il montre comment on crée une application avec ProjectBuilder et InterfaceBuilder (les environnements de développement et de création de GUI de Mac OS X).
*TING!* MJD vient de faire sonner les 4 minutes.
Jonas essaye d'accélérer mais se mélange un peu les pinceaux et n'arrive pas à faire fonctionner sa calculette.
*GONG!* MJD lui signale que son temps est écoulé.
CamelBones - http://camelbones.sf.net/
Rafiq explique dans ce talk que dans certaines secteurs,
comme les finances, les éditeurs logiciels tendent à
écarter les langages comme Perl pour tout rassembler
autour d'API écrites en C. Mais Perl a la possibilité
de s'en sortir grâce à Inline::C, qui permet d'utiliser
de manière simple et rapide du code C en Perl, sans
devoir développer une interface XS. Rafiq montre un
exemple de vieux programme Perl qui a pu être facilement
mis à jour de cette manière.
Christophe s'interroge sur l'avenir de Perl/Tk qui n'a pas été mis à jour depuis longtemps bien que le développement de Tcl/Tk ai récemment repris et qu'une version majeure soit sortie.
Il termine en remontrant les exemples qu'il avait présenté
lors de talk sur Tk::Zinc. Quelqu'un du public demande
s'il peut faire une calculatrice.
Tim propose dans ce talk que les développeurs Perl, maintenant qu'ils ont pris l'habitude d'écrire des séries de tests unitaires, devraient aussi apprendre à créer et maintenir des interfaces d'utilisation stables et cohérentes entre elles. Cela rejoint en partie ce qu'exprimait MJD dans son mini-talk The failure of subclassing on CPAN.
Afin d'étayer son propos, il montre un exemple de refactoring qui échoue par manque de tests unitaires écrits dans le but de vérifier la stabilité de l'API. C'est d'autant plus important dans notre cas que Perl ne vérifie pas du tout les paramètres passés aux fonctions.
Il propose ainsi que les fonctions remplissant des buts
similaires portent le même nom. Il ne prône toutefois pas
un cadre psycho-rigide propre à d'autres langages dit
orientés-objets mais plutôt une convention, de manière
similaire à celle d'appeler new() la fonction de création
des objets. Un point sur lequel il insiste par contre est
que les interfaces devraient rester le plus possible
stables afin de ne pas dérouter l'utilisateur du module.
Design-by-contract in Perl - http://www.lemonia.org/ti/DBCSlide1.htm
Mark présente le module Test::DatabaseRow qui permet
d'écrire des tests sur les données présentes dans une
base de données. Les possibilités du module sont assez
étendues et outre la simple comparaison, on peut aussi
vérifier les valeurs avec des expressions régulières.
Ettore arrive comme beaucoup d'autres avec son portable et le branche. Une partie du public, constatant avec effroi que ledit portable tourne sous Windows, commence à siffler et à huer. MJD calme les esprits et Ettore explique comment Perl lui a permit de créer un système permettant à une université de gérer les notes des étudiants de manière plus simple. Avec comme contraintes intéressantes que tout le parc informatique, serveurs compris, était 100% Windows, et qu'il fallait sortir des fichiers Excel et Word.
Ettore explique que la saisie se fait au travers d'un CGI
(sous IIS évidemment) qui entre les notes dans une base
MS-SQL via DBI, puis que d'autres programmes vont ensuite
extraire ces notes et grâce aux modules Win32::OLE et
SpreedSheet::WriteExcel vont générer les fichiers Word
et Excel désirés. Le système a permit de gérer les notes
de 8 fois plus d'élèves en 6 fois moins de temps.
Le public l'applaudit très chaleureusement pour cet exemple d'utilisation de Perl dans un environnement pourtant si peu pratique.
Perl Success Story: The John Cabot University Professor Course/Evaluation System - http://www.oreillynet.com/pub/wlg/3855
Philippe arrive un portable qui semble un peu vieux mais néanmoins toujours vert (puisque sous GNU/Linux), et démarre sa présentation en mode texte (semblable à celle utilisée par Leopold Tötsch).
Philippe commence par expliquer en anglais qu'étant donné que ce YAPC se déroule à Paris, il fallait quand même bien qu'il y ait une présentation en français. Puis il embraye en français pour parler de l'hypothétique organisation d'un French Workshop, similaire à ce qui s'est fait en Allemagne.
Pendant ce temps, son programme de présentation manifeste sa surprise devant ce changement de langue et décide, semble-t-il de son propre chef, d'occuper le public anglophone en lui racontant des blagues. En anglais.
« I am a poor computer, I will just try to keep you entertained while he is making fun of you in French »
« Quelle est le nom de l'Étoile polaire ? ... Eléonore »
« A French Joke ... Jacques Chirac »
L'ensemble du public, les Frenchies en premier, n'écoute déjà plus du tout Philippe mais reste suspendu aux jeux de mots de son programme. Lui-même a d'ailleurs du mal à rester sérieux confronté à ses facéties (surtout les blagues Carambar).
Maîtrisant à peine son fou rire, il décide de rappeler à son programme qui est le patron et commence à le réprimander. Ce dernier fait la tête et décide de bouder, mais continue finalement à s'exprimer à la place de Philippe, qui renonce, décidément incapable d'en placer une.
La salle est en délire, le public fait un triomphe plus que mérité à Philippe par une ovation debout. Les quelques personnes qui n'applaudissent pas sont celles qui, portables sur les genoux, décrivent la scène sur IRC. MJD vérifie que, malgré les apparences, cette présentation a bel et bien duré moins de cinq minutes.
Quelqu'un demande à voir le programme utilisé. Philippe explique qu'il a en fait préparé sa présentation la matin même et a donc codé à toute allure ce petit morceau de code (une vingtaine de lignes), qui ne fait qu'afficher des slides pendant des durées déterminées, son petit PowerPoint en quelque sorte. Quelqu'un crie « bloatware !». Le public applaudit une nouvelle fois Philippe pour cette éclatante preuve de supériorité sur Microsoft, rejoignant Leopold Tötsch dans la catégorie « j'ai écrit une visionneuse de moins d'un kilo-octet ».
Piers présente de manière originale quelques idées sur les bonnes méthodes de management : en les chantant !
Après avoir terminé sa chanson et pendant que le public l'applaudit, il se rend compte que MJD regarde intensément la liste des Lightnig Talks. Il fait alors signe au public d'arrêter de l'applaudir et recommence à chanter. Entendant cela, MJD relève la tête d'un air surpris et commence à sonner du gong pour signaler que le talk est achevé.
Ce Lightning Talk en contient en fait trois, qui sont présentés en 5 minutes seulement.
Gabor est d'abord venu présenter le groupe de Perl Mongers d'Israël, dont le symbole est une mante religieuse, d'où le titre de sa présentation. En effet, ce groupe très actif a organisé en début juillet le premier YAPC::Israel. Il remercie au passage MJD de s'être déplacé pour le premier YAPC dans cette région du monde, qui n'a duré qu'une journée. Il espère réaliser un YAPC de deux jours l'année prochaine.
Le deuxième sujet est une étude comparative des groupes de mongueurs pour déterminer lequel est le plus gros. Il présente par nombre d'adhérents, où NY.pm est le plus important. Par l'activité de la liste de diffusion, London.pm est le plus loquace avec plus de 800 mails sur un mois. Quelqu'un demande « How many on topic ? » faisant référence au fait que sur london-pm, on parle à peu près de tout (et beaucoup de Buffy), mais seulement très occasionnellement de Perl. Les mails relatifs à Perl doivent d'ailleurs être indiqués Off-Topic ! Paris.pm est cinquième en nombre d'adhérents et second en volume de mails. Le dernier critère à évaluer est le volume d'alcool, qui reste à déterminer.
Considérant que la liste de diffusion constituait le cœur des groupes de mongueurs, il conclue que London.pm et Paris.pm sont les deux groupes de mongueurs les plus actifs, ce qui satisfait pleinement le public.
Il termine enfin sur les futurs YAPC. En 2004 comme en 2003 il y aura quatre YAPC : Israël, Canada, America et Europe dans cet ordre.
Israel.pm - http://www.perl.org.il/
Hendrik présente un langage de programmation, qu'il a appelé Beatnik (son propre pseudonyme, et il s'excuse pour ce manque d'originalité) qui a comme particularité d'être basé sur les règles du Scrabble. En effet cela consiste à utiliser des mots dont la valeur est la somme des valeurs des lettres, en utilisant les valeurs usuelles du Scrabble. Celles-ci variant d'une langue à l'autre, il indique que cela implique de préciser la langue utilisée, un même mot n'ayant pas la même valeur dans deux règles différentes. Uri Guttman râle parce qu'il ne prend pas en compte les mots compte double et mots compte triple.
Il termine en montrant un programme, une pleine page remplit
de mots, qui est évidemment un hello world. MJD semble
admiratif devant cet exemple assez étonnant. Le module
Acme::Beatnik sera bien évidemment disponible sur le CPAN.
Jaap présente le Zoidberg Perl Shell, qui est comme son l'indique un shell écrit en Perl. Il précise qu'il est actuellement suffisamment avancé pour que lui-même s'en serve au quotidien et montre quelques unes de ses fonctionnalités.
Zoidberg Perl Shell - http://zoidberg.sf.net/
Ronan semble avec ce talk vouloir lancer un bon gros troll un peu baveux en expliquant pourquoi « Perl sucks » et « Ocaml rocks » concernant leur manière respective de gérer les objets. Il propose que Perl imite Ocaml et groupe les méthodes dans le compilateur par type de méthode plutôt que par type d'objet. Cela rend l'ajout d'une opération plus simple, mais l'ajout d'un type plus compliqué.
Toutefois personne ne réagit à son troll, peut-être à cause
de l'effet Paris.pm. Ou peut-être parce que personne ne sait
ce qu'est Ocaml ni à quoi ça sert ;-)
Why Ocaml is better than Perl - http://www.inrialpes.fr/sharp/people/lehy/ocaml_vs_perl_commented.pdf
Uri rappelle que WWW::Mechanize est un bon module très
utile pour réaliser des automates naviguant tout seuls
sur la toile pour pêcher des informations.
« XSLT is hard » (il l'a même écrit « XLST » ;-)
Il utilise TT (Template Toolkit) et des tags spécifiques (avec un espace de noms séparé), qui lui laisse faire des transformations à sa manière. Il utilise SAX (qui SUXE, NdMR).
Continuant à prodiguer des conseils de bonne conduite, Tim expose cette fois le cas des wikis et du problème de navigation qui peut découler d'une mauvaise présentation. Il présente quelques approches pour améliorer cette situation.
Wikis & navigation - http://www.lemonia.org/ti/NavSlide0.htm
Earle présente le projet Open Guides qu'on a déjà un peu
vu dans le talk Mapping the wireless revolution on the semantic web
de Jo Walsh. Open Guides est un wiki dopé aux
méta-données, basé sur CGI::Wiki augmenté d'extensions
à eux.
Le but est de fournir un genre de guide touristique ouvert, écrit au fur et à mesure par les personnes qui connaissent les endroits afin de donner les informations les plus précises. Il permet aussi de répondre à des questions cruciales comme « quels sont les bars situés à moins de 300 mètres de tel lieu ? ».
Open Guides - http://www.openguides.org/
La vente aux enchères est dirigée comme il se doit par l'ineffable Greg McCarrol, qui présente infatigablement les livres, t-shirts et autres objets mis en vente. Il est assisté par Uri Guttman, Philippe Bruhat et quelques autres personnes pour la distribution aux acheteurs.
Projeté sur le grand écran derrière Greg, un iBook a été
branché avec en fenêtre de premier plan le canal IRC du
YAPC. Quelques personnes dans la salle transmettent en
temps réel les enchères, voire dans certains cas avec un
peu d'avance, ce qui ne manquera pas de déstabiliser Greg
:-)
Parmi les objets en vente, on trouvait des livres donnés
par O'Reilly (Programming Perl, Programmation en Perl,
mod_perl, Programmation avancée en Perl) et par
Pearson (le fameux Object Oriented Perl de Damian Conway,
Data Munging with Perl, Network Programming with Perl).
Certains titres étant en français, cela nous donne l'occasion
d'entendre Greg massacrer notre belle langue :-)
Seront aussi vendus des autocollants signés par Larry Wall, l'animal en baudruche réalisé par Piers Cawley, plusieurs t-shirts « uniques » de différents groupes de mongueurs dont le dernier exemplaire du t-shirt Perl is my bitch qui sera finalement acheté par Philippe à prix d'or. À la demande de certaines personnes, il met son t-shirt rose en vente, qui partira pour 65 euros. Seront par la suite mis aux enchères le caleçon de MJD (déjà vendu à YAPC aux États-Unis), acheté par Elaine Ashton, puis le soutien-gorge d'Elaine, acheté par Leon Brocard !
Un moment fort fut quand Philippe revint avec son portable et présenta un tableau encadré, l'image originale projetée à l'écran. La partie droite est une photo de Greg McCarroll, la partie gauche un bloc de code Perl assombri dont certains caractères (comme gmc) sont en gras. Il explique que c'est l'assombrissement que Dave Cross lui avait acheté deux ans auparavant lors de la vente aux enchères du YAPC::Europe 2001 à Amsterdam et donne le tableau encadré à Dave. Premier concerné dans cette affaire, Greg imagine que le programme va dire du mal de lui et décide d'acheter le fait ne pas le faire tourner. L'exécution du programme est donc mise aux enchères et fini par monter jusqu'à plus d'une centaine d'euros.
Sachant qu'il risque fort de les payer, Greg met fin à ces
enchères et Philippe lance son programme.
Celui-ci efface l'écran et affiche sur la première ligne de
son terminal une suite aléatoire de caractères qui défilent
comme l'affichage d'un aéroport. Greg se moque de Philippe,
qui ne bronche pas. Le premier caractère se fige sur la lettre
"G", puis après un moment le second sur la lettre "r",
et ainsi de suite jusqu'à afficher la phrase :
Greg McCarroll is my bitch
Tonnerre d'applaudissements pour Philippe qui démontre là encore sa maîtrise du terminal et des programmes assombris.
Le clou de la vente reste néanmoins la décision du changement de la langue des sites web des deux premiers groupes de mongueurs, London.pm et Paris.pm. Les anglais commencent en faisant quelques offres pour que l'anglais soit la langue choisie, ce qui n'emballe personne. Puis Marty Pauley décide d'organiser une mutinerie et crie qu'il veut passer les sites en japonais. Quelques personnes le suivent et une petite bataille commencent entre les nippophiles et les anglophiles.
Ces derniers remportent par leur supériorité numérique et les choses auraient pu en rester là sans Paul Makepeace qui propose 600 euros pour passer la page en espéranto. Stupeur dans la salle, mais Greg se reprend et harangue les londoniens pour qu'ils surenchérissent. Quelques autres personnes soutiennent Paul mais les anglais semblent encore gagner par leur nombre. Mais Paul renchérit à plus de 700 euros et commence à attirer de plus en plus de monde dans son camp. Les anglais essayent de tenir bon, mais Marty réalise un nouveau coup d'éclat en transférant son offre (ainsi que celles des autres personnes qui pariaient sur le japonais) en faveur de l'espéranto.
Lorsque la barre des 1000 euros est dépassée, certains anglais commencent à pâlir, sentant que la victoire pourrait leur échapper. Greg, abasourdi par la teneur que prennent les événements, essaye même de dissuader Paul et ses supporters : « Do you realize that you are offering more than thousand euros to change the main page of the biggest two Mongers groups to Esperanto ??? » Mais la majorité du public est maintenant contre l'idée d'utiliser encore et toujours l'anglais comme langue commune.
Quelqu'un ayant rapidement développé un CGI pour garder le compte des enchères amène son portable à la tribune. Uri prend en charge la mise à jour des résultats. Constatant que le français n'a reçu aucune offre, quelques personnes font des offres symboliques, sachant que cela reste hors de portée. D'autres offres sont aussi proposées pour le Swedish Chef (Bork bork bork!). Mais la guerre entre l'anglais et l'espéranto reprend pour la dernière bataille, qui après des trahisons dans les deux camps s'achève sur la victoire incontestée de l'espéranto pour 1371 euros.
Le public est en délire, sauf quelques anglais qui font triste mine et se demandent pourquoi le monde est si injuste.
Enchaînant rapidement, David Landgren remercie les orateurs et participants, cite les sponsors qui ont financé ce YAPC et annonce que le prochain YAPC::Europe se déroulera à Belfast.
![[IE7, par Dean Edwards]](/images/ie7.gif)
![[Validation du HTML]](/images/xhtml.gif)
![[Validation du CSS]](/images/css.gif)
Copyright © Les Mongueurs de Perl, 2001-2011
pour le site.
Les auteurs conservent le copyright de leurs articles.