![[couverture de Linux Dossiers 2]](http://www.ed-diamond.com/bigres/ldos2.jpg "Linux Dossiers 2")
![[couverture de Linux Magazine 55]](http://www.ed-diamond.com/bigres/lmag55.jpg "Linux Magazine 55")
Article publié dans Linux Magazine 55, novembre 2003. Repris dans Linux Dossiers 2, avril/mai/juin 2004.
Copyright © 2003 - Philippe Blayo.
![[+ del.icio.us]](/images/add-to-delicious.gif)
![[+ Developers Zone]](/images/add-to-dzone.gif)
![[+ Bookmarks.fr]](/images/add-to-bookmarks-fr.png)
![[Digg this]](/images/add-to-digg.png)
![[+ My Yahoo!]](/images/add-to-myyahoo.gif)
Fidèle à sa philosophie, Perl propose plusieurs manières de lancer un processus. Cet article va tenter de montrer à quelles utilisations chacune de ces méthodes peut s'appliquer.
Vous avez pu voir tout au long des articles précédents de cette série qu'une des caractéristiques du langage Perl était : il y a plusieurs manières de faire.
Le lancement et la gestion des processus n'échappent pas à cette règle : Perl propose plusieurs manières d'invoquer et de gérer des processus à partir d'un script ou d'un uniligne.
Ce n'est pas étonnant car l'un des rôles de Perl est de relier des programmes. C'est une des raisons pour lesquelles Perl, ainsi que d'autres langages de scripts, sont parfois qualifiés de langages de glu.
Cet article se propose de décrire les principales approches de haut niveau qui permettent de le faire. Bien que ce soit une tâche relativement ordinaire, il n'existe en effet aucun endroit dans la documentation de Perl où ces informations soient regroupées.
Qu'est-ce qu'un processus ? Disons grossièrement qu'un processus correspond à l'exécution d'un programme. Le noyau crée le premier processus (/sbin/init). Tous les autres processus sont ensuite engendrés par duplication. Le processus auteur de la duplication est appelé processus père. Le nouveau processus est appelé processus fils. Tout processus a un seul processus père. Un père, par contre, peut avoir un nombre quelconque de fils.
Qu'est-on susceptible de lancer depuis un script Perl ? A priori, tout ce qu'on peut être amené à utiliser depuis la ligne de commande d'un shell. C'est-à-dire essentiellement des commandes, éventuellement agrémentées des facilités d'écriture qu'offre la syntaxe d'un shell (on parle parfois de sucre syntaxique). Ces facilités d'écriture du shell, souvent bien utiles, peuvent parfois s'avérer gênantes. Aussi, comme on va le voir, Perl fournit à la fois des moyens de passer par le shell et des moyens d'éviter un tel passage.
Les fonctionnalités des commandes Unix de base sont en grande partie disponibles directement en Perl. Dans ce cas, il peut s'avérer plus judicieux de rester dans les modules de Perl plutôt que de lancer un processus. En ce qui concerne les fonctionnalités qui n'entrent pas dans cette catégorie, elles sont peut-être mises en œuvre dans d'autres scripts Perl, dont il serait possible de faire des modules utilisables directement à travers une API Perl plutôt que par l'intermédiaire du lancement d'un processus. Et s'il s'agit de scripts écrits dans d'autres langages, il est peut-être envisageable de créer des interfaces, au moyen de SWIG par exemple, pour invoquer directement des fonctions en Perl...
Ce genre de raisonnement pourrait nous amener assez loin, en tout cas bien au-delà du cadre de cet article et du langage Perl lui-même. Aussi, tout dépend du but que l'on poursuit en écrivant un code. Perl fournit des fonctions de haut niveau qui permettent d'employer des commandes et des applications avec la même syntaxe que dans une ligne de commande. Par exemple, on se dit parfois qu'il serait bon d'automatiser un traitement qu'on vient de faire plusieurs fois à la main en ligne de commande. La création du script qui automatise ce traitement est dans ce cas grandement facilitée (quelques copier-coller suffisent). Lancer des processus à partir de Perl peut donc permettre de gagner beaucoup de temps de développement. Pour faire du prototypage, c'est très appréciable. Quant aux temps d'exécution et à la portabilité, ce sont là d'autres problèmes (qu'on n'abordera quasiment pas dans cet article).
On peut dire très grossièrement qu'il en existe trois formes différentes (les deux dernières permettent de récupérer la sortie) :
system "commande"; $sortie = `commande`; open SORTIE, "commande |";
Voyons donc en détail ces outils que Perl met à notre disposition.
system()Un premier moyen de lancer un processus fils est la fonction
system() :
system "date";
Ici, le processus fils est la commande Unix date(1). Tout ce que le prompt shell peut interpréter peut être utilisé dans cette chaîne (on précisera plus loin quel shell réalise cette interprétation).
Le processus fils hérite des entrées et sorties standards ainsi
que de la sortie d'erreur de Perl. Aussi, la sortie de cette
commande date(1) aboutira là où le STDOUT de Perl était dirigé
(par défaut, l'écran).
Il n'est donc pas possible de récupérer facilement
cette sortie dans le script Perl d'où la commande a été lancée.
Il est bien entendu possible de la rediriger vers un
fichier. Mais si dans la suite du script on souhaite accéder
à cette sortie, cela signifie qu'il faut ouvrir ce fichier, le lire
puis le refermer. Si une écriture sur disque n'est pas indispensable,
on préférera d'autres solutions qui seront abordées dans la suite.
La commande peut être aussi complexe que nécessaire, dans la mesure où /bin/sh peut l'exécuter :
system "for i in *; do echo __ \$i __; cat \$i; done";
Ici, on affiche le contenu d'un répertoire, fichier par fichier.
Les variables $i sont protégées par une barre oblique inversée (\)
parce que Perl
les aurait remplacées par leur valeur courante dans le script Perl
alors qu'on souhaite que le shell voit ses propres variables $i à
la place.
Une solution est d'utiliser les apostrophes (' ou simple quotes)
à la place des guillemets (" ou double quotes),
puisqu'elles ne réalisent pas l'interpolation
des variables Perl :
system 'for i in *; do echo __ $i __; cat $i; done';
Cette commande serait plus lisible si elle s'étendait sur plusieurs lignes. Ce qui se fait très simplement avec une citation orientée ligne (here-document ou document « ici-même ») :
system <<'FIN'; for i in * do echo __ $i __ cat $i done FIN
Cette citation orientée ligne est initiée par l'opérateur <<
suivi d'un identifiant qui
déterminera la fin de la citation (FIN dans notre cas).
Toutes les lignes qui se trouvent entre les deux occurrences
de l'identifiant FIN sont transformées en une chaîne, qui constitue
l'argument de system().
La manière dont la transformation est effectuée dépend des
éventuels caractères de ponctuation qui entourent l'identifiant.
En l'absence de tels caractères, c'est le comportement des
guillemets qui est utilisé par défaut. Aussi des apostrophes ont-elles
été ajoutées pour empêcher l'interpolation des $i qui doivent
être passés au shell.
Une attention particulière doit être portée à cette syntaxe :
la seconde occurrence de l'identifiant doit apparaître seule sur la
ligne de terminaison (sans ponctuation et sans espaces).
Par ailleurs, pendant que le processus fils s'exécute, Perl est arrêté. Ainsi, si une commande nécessite 40 secondes pour s'exécuter, votre script est arrêté pendant 40 secondes. Il est possible de faire se dérouler un processus en tâche de fond par l'intermédiaire du shell :
system "commande_qui_prend_du_temps avec ses arguments &";
Attention cependant : dans ce cas plus moyen d'interagir avec la commande, ni même de connaître son numéro de processus pour la tuer ou vérifier qu'elle est encore en vie.
On n'abordera que plus tard les cas où cette interprétation par
le shell peut s'avérer problématique.
Mais signalons dès maintenant qu'il existe une autre version de
system() qui évite tout passage par le shell.
Cette version utilise non plus un unique argument
mais plusieurs. Nous y reviendrons le moment venu.
exec()La fonction exec() se comporte comme system() pour tous les
aspects déjà évoqués.
La seule différence est qu'au lieu de créer un
processus fils pour exécuter la commande en argument, le processus perl
devient cette commande.
Par exemple :
exec "date";
À partir du moment où la commande date(1) a commencé à s'exécuter, on quitte
perl pour ne plus y revenir. L'interpréteur perl est remplacé par la
commande date(1). La seule raison de placer du code Perl après
un exec() est d'expliquer que la commande date(1) n'a pu être trouvée
dans le PATH :
exec "date"; die "date non trouvée dans $ENV{PATH}";
Placer autre chose qu'un die(), un warn() ou un exit() après un
exec() provoque d'ailleurs un avertissement si on emploie l'option -w
(ou use warnings depuis Perl 5.6) :
$ perl -we 'exec "date"; print "date non trouvée";'
Statement unlikely to be reached at -e line 1.
(Maybe you meant system() when you said exec()?)
Disons d'une manière imagée qu'avec system() on embarque pour un voyage
aller-retour, alors qu'avec exec(), on prend un aller simple.
Si on se trouve encore sur le quai après un exec(), c'est que le départ
n'a pas été possible.
Randal L. Schwartz emploie pour sa part une autre métaphore pour
exprimer cette différence entre system() et exec() :
il compare system() à un appel de fonction et exec() à un goto.
Remarquez d'ailleurs que l'utilisation d'exec() empêchera l'appel des
blocs END de votre code et des méthodes DESTROY de vos objets.
Pourquoi employer exec() plutôt que system() ?
Il peut s'avérer intéressant d'employer exec() dans les cas où Perl est
utilisé pour préparer l'environnement d'une commande dont l'exécution
prendra du temps :
$ENV{DATABASE} = "ma_base_de_donnee"; $ENV{PATH} = "/usr/bin:/bin:/opt/base_de_donnee"; chdir "/usr/lib/mes.informations" or die "Changement de répertoire impossible : $!"; exec "commande_qui_prend_du_temps"; die "commande_qui_prend_du_temps non trouvée dans $ENV{PATH}";
Remplacer exec() par system() aurait eu pour effet de
laisser tourner un programme Perl inutile qui attendrait juste que
commande_qui_prend_du_temps s'achève.
Pour prendre un exemple plus concret d'utilité de exec(), construisons
une version Perl de la commande dvipdf. Cette commande transforme un
document au format DVI (un des formats de sortie de LaTeX) en un
fichier PDF.
Elle se présente à l'origine sous la forme d'un petit script shell
dont le but est de lancer une suite de commandes munies des bonnes options.
Il s'agit essentiellement, quand on souhaite générer un fichier
destination.pdf à partir d'un fichier source.dvi, de ne pas avoir
à se souvenir d'un enchaînement du type
dvips -q -f source.dvi | gs -q -dNOPAUSE -dBATCH -sDEVICE=pdfwrite -sOutputFile=destination.pdf -c save pop -.
Une telle inclusion dans un script permet, en plus, de construire à partir
du préfixe au .dvi le nom du fichier destination.pdf quand
ce dernier n'est pas spécifié :
#!/usr/bin/perl -w
# Version Perl de dvipdf.
use strict;
# séparation des arguments
my $options = join ( ' ', grep { /^-\S+/ } @ARGV ); # options
my @fichiers = grep { !/^-\S+/ } @ARGV; # source et autres
if ( $#fichiers < 0 or $#fichiers > 1 ) {
use File::Basename;
print "Usage: ", basename($0),
" [options...] source.dvi [destination.pdf]\n";
}
my $source = $fichiers[0];
my $destination;
if ( $#fichiers == 0 ) {
$fichiers[0] =~ s/.dvi$//;
$destination = "$fichiers[0].pdf";
}
else {
$destination = $fichiers[1];
}
my $commandes =
"dvips -q -f $source |"
. " gs -q -dNOPAUSE -dBATCH -sDEVICE=pdfwrite"
. " -sOutputFile=$destination $options -c save pop -";
# fin des préparatifs, exécution des commandes
exec $commandes;
On entrevoit ici qu'un exec() peut nécessiter un gros travail de
préparation.
Signalons qu'outre le gain en temps d'exécution par rapport à la version
shell, cette version Perl offre plus de souplesse : elle n'oblige pas à
placer les fichiers source et destination après les options (ordre
à respecter avec la version shell).
Le terme d'apostrophe inversée désigne le caractère `
appelé backquote ou backtick en anglais (quote désignant l'apostrophe).
Quand on invoque une commande pour disposer de sa sortie sous la forme d'une chaîne de caractères, la manière la plus simple de procéder est d'employer les apostrophes inversées :
$maintenant = `date`;
La sortie standard de date(1) est stockée sous la forme d'une
chaîne d'une trentaine de caractères suivie d'un saut de ligne.
Tout ce qui est envoyé vers la sortie standard est capturé sous
la forme d'une chaîne de caractères, renvoyée par les apostrophes inversées,
et, dans notre cas, stocké dans $maintenant.
Si la sortie comporte plusieurs lignes, toutes les lignes se
retrouvent les unes à la suite des autres dans la chaîne.
Cette chaîne peut être divisée
en lignes par un split() sur les sauts de ligne, mais la manière
la plus simple est d'utiliser les apostrophes inversées en contexte
de liste :
@logins = `who`;
Ici, @logins contiendra une entrée pour chacune des lignes de la
sortie de la commande who. On peut analyser cette sortie au moyen
d'une boucle comme celle qui suit :
for( `who` ) { ($utilisateur, $tty, $date) = /^(\S+)\s+(\S+)\s+(.*)/; $logins{$utilisateur}{$tty} = $date; }
Chaque itération de la boucle décrit un terminal différent avec la date depuis laquelle le dernier utilisateur s'y trouve. Ces informations sont placées dans un hash à deux niveaux indexé par le nom de l'utilisateur puis celui du terminal. Ceci fait, on peut afficher le tout trié par utilisateur :
for $utilisateur ( sort keys %logins ) { for $tty ( sort keys %{ $logins{$utilisateur} } ) { print "$utilisateur se trouve sur $tty depuis ", "$logins{$utilisateur}{$tty}\n"; } }
La première boucle peut profiter des variables par défaut pour obtenir une écriture plus concise :
for( `who` ) { /^(\S+)\s+(\S+)\s+(.*)/; $logins{$1}{$2} = $3 }
Les variables globales $1, $2 et $3 correspondent
aux trois chaînes capturées par les parenthèses de l'expression
régulière (l'utilisateur, le terminal et la date).
Les apostrophes inversées se comportent comme des guillemets en ce qui concerne
l'interpolation de leur contenu. Ainsi, les caractères d'échappement
comme \n et \t peuvent être utilisés et les variables Perl
sont interpolées. Une première conséquence de cette interpolation est que,
comme pour system(), on peut être amené à protéger certains caractères
spéciaux :
$fichiers = `for i in *; do echo __ \$i __; cat \$i; done`;
Il est également possible d'utiliser l'opérateur qx/CHAINE/,
équivalent aux apostrophes inversées, mais qui donne accès aux
apostrophes (simples) :
$fichiers = qx'for i in *; do echo __ $i __; cat $i; done';
L'autre conséquence de l'interpolation sera développée dans le chapitre sur le passage par le shell.
Si on souhaite récupérer la sortie d'erreur plutôt que la sortie standard, on peut utiliser les opérateurs de redirection du shell (l'ordre est ici très important) :
$sortie_erreur = `commande 2>&1 1>/dev/null`;
2>&1 provoque d'abord la redirection de la sortie d'erreur
(désignée par le chiffre 2) vers l'endroit où la sortie standard
(désignée par 1) aboutit par défaut (c'est ce que les
apostrophes inversées récupéreront). Pour que les apostrophes inversées
ne récupèrent pas également la sortie standard, cette dernière est
réorientée vers /dev/null (1>/dev/null).
Si l'ordre avait été inversé (1>/dev/null 2>&1), les sorties
auraient toutes deux abouti dans /dev/null, et les apostrophes
inversées n'auraient rien renvoyé.
open()En Perl, la fonction open() ne sert pas seulement à accéder à des
fichiers.
Si le deuxième argument d'un open() s'achève par une barre verticale
(le symbole tube), Perl le traite comme une commande à lancer plutôt que
comme un nom de fichier :
open DATE, "date|";
Au moment où cette ligne est exécutée, une commande date(1) est lancée dont
la sortie standard aboutit dans le manipulateur de fichier DATE
pour y être lue.
On parle de tube ou de conduit car la sortie de la commande se déverse
dans une sorte de fichier temporaire présent uniquement en mémoire.
Ce fichier temporaire est justement appelé un tube (pipe en anglais).
Le manipulateur DATE permet de lire ce fichier comme
s'il s'agissait d'un fichier normal (sur disque).
On peut donc y lire la sortie en utilisant les
opérations habituelles sur les manipulateurs de fichiers :
$maintenant = <DATE>;
De la même manière que pour les fichiers, le manipulateur est créé par le
open() et disparaîtra après un close(). Contrairement au manipulateur
d'un fichier classique, il n'est par contre pas possible d'y accéder
par l'intermédiaire des fonctions tell() et seek().
Le processus tourne en parallèle de Perl, et se coordonne avec lui de la même manière que pour un tube standard. Donc si la commande date(1) envoie sa sortie avant que Perl ne soit prêt, il attendra, et si Perl lit avant que date(1) ne soit prêt à écrire, le processus Perl sera arrêté jusqu'à ce que la sortie soit disponible, sans consommation de CPU.
Par rapport aux apostrophes inversées, cette méthode présente l'avantage de pouvoir traiter la sortie au fur et à mesure de son écriture. En effet, si la sortie est volumineuse, la récupérer d'un seul coup va occuper de la mémoire, que ce soit par l'intermédiaire des apostrophes inversées :
@sortie = `genere_sortie_volumineuse`;
ou bien par l'intermédiaire d'une lecture en contexte de liste :
open SORTIE, "genere_sortie_volumineuse |"; @sortie = <SORTIE>; close SORTIE;
Dans les deux cas, le tableau @sortie peut occuper beaucoup
de place en mémoire.
Une solution est d'utiliser le manipulateur de fichier fourni par
open() en contexte scalaire :
open SORTIE, "genere_sortie_volumineuse |"; while( my $ligne = <SORTIE> ) { # la ligne courante est stockée dans $ligne ... } close SORTIE;
Rappelons que dans ce cas d'une affectation simple, Perl traduit
automatiquement cette boucle while en :
while( defined( my $ligne = <SORTIE> ) ) { ... }
ce qui évite d'être à la merci de bugs subtils (comme l'avait précisé BooK dans son article sur les variables de LinuxMag 52).
Avec cette construction, la sortie est traitée ligne par ligne,
au fur et à mesure de son écriture par genere_sortie_volumineuse.
On stocke ainsi une seule ligne à la fois plutôt que l'ensemble des
lignes, ce qui réduit d'autant l'espace mémoire occupé.
La fonction open() renvoie undef dans le cas où la duplication
de processus (le fork) n'a pu être réalisée. On peut donc le
tester au moyen d'un ou :
open SORTIE, "commande |" or die "impossible de dupliquer le processus : $!";
Il faut tout d'abord avoir à l'esprit que le shell que perl utilise
par défaut est sh(1), ou celui vers lequel pointe /bin/sh
s'il s'agit d'un lien (vers bash(1) par exemple).
Ce n'est donc pas nécessairement le shell depuis lequel l'interpréteur perl
a été lancé, ni celui indiqué par $ENV{SHELL}.
C'est vrai de tout passage par le shell, qu'il soit provoqué par
open(), system(), exec() ou les apostrophes inversées.
Le sh(1) traditionnel ne permet pas,
par exemple, de combiner sur une même ligne un export et une
affectation. Le export FOO=bar d'usage avec d'autres shells
peut donc provoquer une erreur, comme sous Solaris et Tru64 (ci-dessous
avec Solaris) :
$ ls -l /bin/sh
[...] 95488 Apr 7 2002 /bin/sh
$ perl -e 'system q{export FOO=bar && echo $FOO};'
sh: FOO=bar: is not an identifier
Cette erreur ne se produit cependant pas sous les nombreuses distributions Linux qui font pointer sh(1) vers bash(1) :
$ ls -l /bin/sh
[...] /bin/sh -> bash
$ perl -e 'system q{export FOO=bar && echo $FOO};'
bar
L'erreur ne se produit pas non plus sous FreeBSD et Mac OS X.
En dehors de ces variations de syntaxe, le passage par le shell peut représenter en lui-même un problème. C'est l'objet de ce qui suit.
system() et exec()Si l'argument passé à system() ne contient
aucun caractère susceptible d'avoir une signification particulière
en shell ($, ?, *, ...), Perl évite tout passage par le shell
et invoque le programme directement. Il peut s'avérer nécessaire
d'ajuster $ENV{PATH} avant d'appeler system(), de manière
à ce que le programme soit trouvé au bon endroit.
Ce passage par le shell peut poser problème.
Imaginons qu'on veuille chercher au moyen d'un grep
les occurrences d'une variable scalaire dans plusieurs fichiers :
system "grep $cherche fichier1 fichier2 fichier3";
Si $cherche est une chaîne aussi simple que "Soleil", aucun problème.
Mais si elle est plus compliquée comme "Voie Lactée", on se trouve
face à un problème, car elle est interpolée comme suit :
system "grep Voie Lactée fichier1 fichier2 fichier3";
qui cherche Voie dans les quatre autres noms, y compris un
fichier nommé Lactée. On a toutes les chances de voir la
commande grep afficher un message d'erreur du type :
grep: Lactée: Aucun fichier ou répertoire de ce type
On peut tenter de résoudre le problème en plaçant $cherche entre
apostrophes :
system "grep '$cherche' fichier1 fichier2 fichier3";
Cela fonctionne pour Voie Lactée, mais pas pour
aujourd'hui. Et si on change les apostrophes du shell
pour des guillemets, un problème surviendra si $cherche
contient des guillemets.
Heureusement, on peut éviter complètement le shell en utilisant
la version de system() à plusieurs arguments :
system "grep", $cherche, "fichier1", "fichier2", "fichier3";
Quand system() reçoit plusieurs arguments, le premier argument
doit être un programme accessible par le PATH. Les arguments
restants sont passés directement au programme, sans interpolation
par un shell. Ainsi, s'il s'agit d'un autre script Perl,
les éléments d'@ARGV dans le programme appelé
sont exactement ceux de cette liste passée en argument de system().
Comme on n'invoque plus de shell, des fonctionnalités comme les redirections d'entrée/sorties ne sont plus accessibles. Cette méthode n'est donc pas dénuée d'inconvénients, mais on vient de voir son utilité. Elle est également un peu plus sûre : il ne se trouvera pas de shell pour trébucher sur un saut de ligne ou un point-virgule introduit dans l'une des chaînes par un utilisateur malveillant.
En ce qui concerne exec(), il existe comme on l'a déjà mentionné
une version à plusieurs arguments. Elle se comporte exactement de la même
manière que celle de system(), sauf bien entendu que dans le cas
d'exec() le processus perl est remplacé par le nouveau processus.
On l'a déjà dit, les apostrophes inversées se comportent comme des guillemets
en ce qui concerne l'interpolation de leur contenu. On retrouve donc les
inconvénients de la version à un seul argument de la fonction system() :
@lignes = `grep $cherche @fichiers`;
Si $cherche contient des espaces ou d'autres caractères reconnus par le
shell, les mêmes problèmes se présentent.
Mais dans le cas des apostrophes inversées, il n'existe pas de version à
plusieurs arguments.
Comme on va le voir, une solution est d'utiliser un cas particulier
de open().
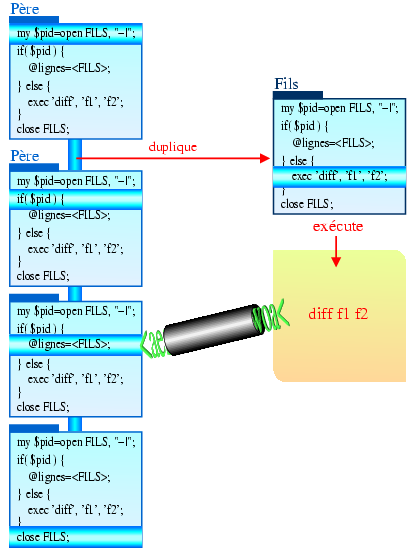
open()Jusqu'à présent, toutes les méthodes qu'on a vues exécutaient une commande extérieure au script appelant. Pour cela, elles réalisaient une duplication de processus (fork) suivi du remplacement du processus fils par la commande extérieure à exécuter (exec).
Il existe une forme de open() (l'ouverture du "fichier" -|) qui
permet de réaliser la duplication de processus sans remplacement du
processus fils :
open FILS, "-|";
On peut ainsi écrire le code à exécuter par le fils dans le
script du père. Pour cela, il faut pouvoir différencier le
père du fils dans le script lui-même. La valeur de retour du
open() permet de le faire : open() renvoie
0 au fils et une valeur non nulle au père (tout comme fork()).
Il suffit donc de tester cette valeur :
my $pid = open FILS, "-|"; die "Impossible de faire la duplication" unless defined $pid; if ($pid) { # le père } else { # le fils }
Il s'agit du numéro de processus du fils (pid pour
Process ID en anglais), mais nous n'en aurons pas l'utilité.
La sortie du fils est reliée au manipulateur de fichier FILS.
Le père peut ainsi lire très simplement cette sortie :
my $pid = open FILS, "-|"; if ($pid) { # le père $maintenant = <FILS>; # lit la sortie du fils } else { # le fils print scalar localtime, "\n"; # écrit la date exit 0; }
Et $maintenant contient la sortie du processus fils.
On peut également réaliser un exec() :
my $pid = open FILS, "-|"; if ($pid) { # le père while ( my $ligne = <FILS> ) { # lit la sortie du fils # faire des choses intéressantes avec $ligne } } else { # le fils exec 'diff', 'fichier1', 'fichier2'; die "diff introuvable : $!"; }
Il s'agit de la version à plusieurs arguments de exec() :
elle évite donc tous les ennuis liés au shell.
Cela résout le problème posé plus haut par l'emploi des
apostrophes inversées.
Si l'on souhaite tester la réussite du open(), il n'est
plus possible d'utiliser la construction or die employée
plus haut. Le résultat du open() serait en effet toujours
considéré comme faux dans le fils (le open() y renvoie 0).
Il faut donc réaliser le test avant :
my $pid = open FILS, "-|"; if ( !defined $pid ) { die "duplication impossible : $!"; } elsif ($pid) { # le père } else { # le fils }
Une construction un peu plus idiomatique pourrait également être employée :
my $pid = open FILS, "-|"; die "duplication impossible : $!" unless defined $pid; ...
Précisons que -| est un cas particulier de la forme
open F, "commande |" qui se duplique puis exécute commande et
garde un tube dessus. Le - signifie qu'il n'y a pas de commande
exécutée après la duplication.
Notez qu'il existe un autre fichier spécial, |-, qui peut être utilisé
avec open() pour créer un manipulateur de fichier en écriture. Le père
pourra alors écrire au fils (on retourne le sens du tube, et on s'approche
du thème de la communication inter-processus).
Il existe des fonctions de plus bas niveau comme fork(),
waitpid() ou pipe() qui permettent d'invoquer les appels systèmes
Unix sous-jacents. Comme cet article concerne les fonctions
de haut niveau, nous nous limiterons à en donner un
exemple ici (voir notamment
les sections correspondantes de perlfunc(1) pour plus de
détails).
Reprenons le open() du "fichier" -| qui
avait pour but de
s'affranchir des problèmes dus aux caractères spéciaux.
Voyons comment cet exemple s'écrit avec les fonctions de plus
bas niveau pipe(), fork() et waitpid() :
pipe( LIRE, ECRIRE ); if ( my $pid = fork ) { # le père close ECRIRE; $maintenant = <LIRE>; # lit la sortie du fils close LIRE; waitpid( $pid, 0 ); } else { # le fils die "duplication impossible : $!" unless defined $pid; close LIRE; print ECRIRE scalar localtime, "\n"; # écrit la date close ECRIRE; exit 0; }
Tout comme open(), fork() retourne 0 au fils et le
numéro du fils ($pid) au père.
Le pipe(LIRE, ECRIRE) de la première ligne permet de créer un
tube avec ses deux extrémités : LIRE pour la lecture et ECRIRE
pour l'écriture.
Le père va lire dans ce tube ce qu'y écrira son fils.
Pour cela, le père doit d'abord fermer l'extrémité ECRIRE.
Après avoir achevé la lecture, il ferme l'extrémité LIRE
puis attend la fin de son fils par un waitpid($pid,0)
(le 0 du second argument détermine le comportement de waitpid() :
attendre le processus de numéro $pid spécifié en premier
argument).
De son côté le fils fait le contraire : il ferme LIRE, écrit
dans le tube puis ferme ECRIRE.
C'était quand même beaucoup plus simple avec open()
(pas besoin de gérer le tube notamment).
De la même manière qu'en shell, chaque processus retourne un
état de sortie quand il s'achève. Et comme en shell, l'état
de sortie du dernier processus se trouve dans une variable
appelée $?. On va reprendre dans ce qui suit les différentes
manières de lancer des processus évoquées jusqu'à présent
et voir pour chacune d'entre elles comment récupérer et utiliser
cet état de sortie.
$?La variable globale $? contient donc l'état de sortie
du dernier processus.
Il s'agit de la valeur retournée par l'appel système wait(2)
(ou waitpid(2)).
C'est-à-dire que si le processus fils s'achève en renvoyant la
valeur zéro (tout s'est bien passé), $? renverra également
zéro. Toute valeur non-nulle est décalée à gauche de 8 bits
(c'est-à-dire multipliée par 256). Si un signal a tué le processus,
son numéro est ajouté à cette valeur (se référer à signal(7)
pour les numéros de signaux). Si un fichier core a été
généré, le nombre 128 est également ajouté. Donc pour extraire les
caractéristiques de $?, on peut procéder comme suit :
$status = $? >> 8; # valeur de sortie $signal = $? & 127; # signal qui a tué le processus $core_dumped = $? & 128; # vrai si c'était un core dump
ou bien d'une manière plus portable (et plus explicite) en utilisant
les macros W*() de l'extension POSIX :
use POSIX qw( :sys_wait_h ); if ( WIFEXITED($?) ) { # vrai pour une fin normale $status = WEXITSTATUS($?); # état de sortie } elsif ( WIFSIGNALED($?) ) { # vrai si tué par un signal $signal = WTERMSIG($?); # numéro du signal }
La génération d'un fichier core n'étant pas un concept portable, il n'existe pas d'équivalent pour la tester.
Notons qu'un use POSIX qw( :sys_wait_h )
a été préféré à un simple use POSIX.
Ce dernier est déconseillé car il provoque
l'exportation dans l'espace de nommage main:: de l'ensemble des symboles POSIX, ce qui est assez lourd.
Il est préférable de n'exporter que le nécessaire.
La documentation de POSIX n'est pas très claire sur
ce sujet, mais la liste qu'on trouve à la fin de cette documentation
correspond aux fichiers .h où les macros et constantes sont définies.
Il faut également connaître le chemin standard de ces fichiers...
Par exemple (extraits) :
TIME
Constants
CLK_TCK CLOCKS_PER_SEC
Le fichier concerné ici est time.h. Pour accéder à ces constantes,
il faudrait donc les précéder d'un use POSIX qw( :time_h ).
WAIT
Constants
WNOHANG WUNTRACED
Macros
WIFEXITED WEXITSTATUS WIFSIGNALED WTERMSIG ...
Cette fois, le fichier concerné est sys/wait.h, d'où le
use POSIX qw( :sys_wait_h ) vu plus haut.
system()La fonction system() retourne la valeur de la variable $?.
Ce qui signifie comme on vient de le voir que si le processus fils
s'achève en renvoyant la valeur zéro,
system() renverra également zéro.
Comme l'association de zéro à un comportement correct (tout s'est bien
passé) entre en contradiction avec l'usage le plus courant des tests
en Perl, il n'est pas possible d'utiliser directement la construction
classique or die (employée notamment avec open() pour
open or die).
La manière la plus simple de contourner le problème est
d'inverser la sortie de system() avec un "non" logique :
!system "commande_qui_peut_echouer" or die "échec";
Une autre manière moins concise, mais peut-être plus intuitive est de tester explicitement l'égalité avec zéro :
system ( "commande_qui_peut_echouer" ) == 0 or die "échec";
Une dernière possibilité est d'utiliser and plutôt que or
(ce qui permet de tester directement la sortie) :
system "commande_qui_peut_echouer" and die "échec";
Dans ce dernier cas, le die "échec" n'est évalué que si system()
renvoie la valeur non nulle d'un code d'erreur
(considérée comme vraie par Perl).
Cette valeur de retour peut être utilisée pour un traitement plus
fin que la réussite ou l'échec.
Par exemple, les commandes diff(1) et cmp(1) renvoient 0 si
les deux fichiers qu'on leur passe en paramètres sont identiques et
1 s'ils diffèrent :
# comparaison de deux fichiers system "cmp fichier1 fichier2"; # gestion plus fine de la valeur retournée par cmp if ( $? == 0 ) { # les deux fichiers sont identiques } elsif ( $? == 1 ) { # les deux fichiers diffèrent } elsif ( $? >= 2 ) { # un problème est survenu (fichier inaccessible, ...) }
De la même manière, la commande grep(1) renvoie 1 si aucune
occurrence n'est présente dans les fichiers passés en arguments :
system "grep", $cherche, "fichier1", "fichier2", "fichier3"; # gestion de la valeur retournée par grep if ( $? == 0 ) { # $cherche est présent dans au moins un des fichiers } elsif ( $? == 1 ) { # $cherche n'apparaît dans aucun fichier } elsif ( $? >= 2 ) { # un problème est survenu }
La variable $? est mise à jour après l'exécution de la commande.
C'est donc cette variable qu'il faut examiner :
# différences entre deux fichiers @differences = `diff fichier1 fichier2`; # gestion de l'état de sortie de diff if ( $? == 0 ) { # les deux fichiers sont identiques } elsif ( $? == 1 ) { # les deux fichiers diffèrent foreach (@differences) { # traiter les différences } } elsif ( $? >= 2 ) { # un problème est survenu (fichier inaccessible, ...) }
open()Attention ! Avec la fonction open() la variable $?,
dépositaire de l'état de sortie, n'est pas mise à jour après
l'exécution de la commande.
Il faut attendre que le close() sur le manipulateur de fichier ait
été réalisé pour que $? soit mise à jour :
$? = 99; # pour les besoins de la démonstration open DATE, "date|"; $date = <DATE>; print $?; # affiche 99 close DATE; print $?; # affiche 0
Et donc si l'on reprend l'exemple de l'état de sortie de diff(1), on obtient un enchaînement du type :
open MANIPULATEUR, "diff fichier1 fichier2|"; # $? ne contient pas l'état de sortie de diff @lignes = <open>; # $? ne le contient toujours pas close MANIPULATEUR; # $? contient l'état de sortie de diff if ( $? == 0 ) { # les deux fichiers sont identiques } ...
Il faut garder à l'esprit que lancer un processus peut avoir un prix
(la duplication consomme des ressources)
et se traduit par une perte de portabilité.
Donc pensez à utiliser les équivalents Perl des commandes Unix.
Par exemple ne pas employer rm(1) alors que l'équivalent Perl
unlink() existe :
system 'rm', @fichiers; # pas portable
peut être remplacé par :
unlink @fichiers; # portable
Un autre exemple courant : pour obtenir le nom du script en train de s'exécuter, il est inutile d'écrire :
$programme = `basename $0`; chomp $programme;
qui peut être avantageusement remplacé par :
use File::Basename; $programme = basename $0;
Tentons un petit résumé de l'essentiel à savoir.
Si on utilise system(),
Si on utilise les apostrophes inversées,
Si on utilise open DESC, "|",
Et la seule différence entre system() et exec() est qu'on ne
reprend pas la main après un exec() (sauf éventuellement pour
signaler son échec).
Perl offre plusieurs manières différentes pour lancer des processus. Cela pourrait donner à penser qu'il est difficile de choisir laquelle est la bonne. Il n'en est rien. Il suffit de savoir dans quel but on lance une commande. Un passage par le shell est-il nécessaire ? A-t-on besoin de récupérer la sortie ? Si oui, cette sortie est-elle volumineuse ?
Tout d'abord abordons la question du shell.
Si un passage par le shell pose problème, il faut employer la version à
plusieurs arguments de system() (ou exec()). Si on veut récupérer la
sortie, il faut combiner open() et exec().
Considérons maintenant le cas où un passage par le shell est
possible et qu'on souhaite récupérer la sortie.
Si cette sortie n'est pas trop volumineuse,
les apostrophes inversées constituent la manière la plus simple
et la plus concise. Si par contre la sortie est susceptible
d'occuper trop d'espace, mieux vaut passer par un open() et la
traiter ligne par ligne.
Enfin, si la commande exécutée prend du temps, il peut s'avérer
préférable d'achever le script au moyen d'un exec() plutôt que
de laisser tourner le processus du script en attente en
parallèle.
La documentation sur system(), exec(), open(), wait(), ...
Le très complet tutoriel sur open().
Les sections Utilisation de open() pour la CIP et
Ouvertures sûres d'un tube contiennent des détails sur
l'utilisation de open() pour la communication inter-processus.
La documentation sur les apostrophes inversées.
Pour des informations sur les aspects portabilité.
Un bon endroit pour trouver la réponse à une question précise.
Les pages de manuel des appels systèmes wait(2) et waitpid(2).
Les numéros de signaux.
Un article en anglais de Randal L. Schwartz sur les nombreuses manières de lancer un processus en Perl. Il est disponible à l'adresse http://www.stonehenge.com/merlyn/LinuxMag/col05.html
L'article de BooK dans Linux Magazine 52 comporte une partie
sur les variables d'erreur ainsi que des précisions et un exemple
(de Jean Forget) sur la subtilité qui caractérise la boucle while.
http://articles.mongueurs.net/magazines/linuxmag52.html
La documentation de l'extension standard POSIX.
Philippe Blayo
Philippe tient à remercier les membres de l'association Les Mongueurs de Perl pour leurs remarques et toutes les relectures effectuées. La méthode pour déterminer précisément, à partir de la documentation, quels exports réaliser en fonction des macros POSIX a été indiquée par BooK (Philippe Bruhat).
![[IE7, par Dean Edwards]](/images/ie7.gif)
![[Validation du HTML]](/images/xhtml.gif)
![[Validation du CSS]](/images/css.gif)
Copyright © Les Mongueurs de Perl, 2001-2011
pour le site.
Les auteurs conservent le copyright de leurs articles.