![[couverture de Linux Magazine 65]](http://www.ed-diamond.com/bigres/lmag65.jpg "Linux Magazine 65")
Article publié dans Linux Magazine 65, octobre 2004.
Copyright © 2004 - Jérôme Fenal.
![[+ del.icio.us]](/images/add-to-delicious.gif)
![[+ Developers Zone]](/images/add-to-dzone.gif)
![[+ Bookmarks.fr]](/images/add-to-bookmarks-fr.png)
![[Digg this]](/images/add-to-digg.png)
![[+ My Yahoo!]](/images/add-to-myyahoo.gif)
Une fois n'est pas coutume, il y aura peu de Perl ce mois-ci chez les Mongueurs.
En effet, nous allons bientôt parler du module Net::LDAP, mais avant de ce
faire, une bonne introduction s'impose, ce que nous ferons ce mois-ci, avec
l'installation de OpenLDAP.
Le mois prochain, nous verrons une utilisation avancée de OpenLDAP, avec
l'écriture de schéma et la mise en haute disponibilité via la réplication.
Ensuite, un des contextes dans lequel l'utilisation d'un annuaire est
intéressante est la centralisation des comptes utilisateurs Unix/Linux. Et c'est
là que nous verrons en détail l'utilisation de Net::LDAP.
Mais en attendant, je vous souhaite une bonne lecture à la découverte de LDAP.
LDAP est un protocole d'accès à un annuaire X.500, normalisé à la fin des années 1990 ; X.500 étant une norme monstrueuse pour la gestion d'annuaire sur des réseaux ISO (vous connaissez les couches ISO ?, ou encore les protocoles réseaux ISO comme DECnet Phase V ou plus proche de nous ISO/DSA de Bull).
LDAP, donc, dont l'acronyme est Lightweight Directory Access Protocol, a très rapidement évolué de l'accès à un annuaire X.500 à la gestion complète d'un annuaire pour les environnements non X.500. C'est ainsi que sont sortis les annuaires de Netscape et que tout le monde a suivi. Dans le camp du libre, OpenLDAP est un projet qui a démarré en août 1998, sur la base de la mise en œuvre de LDAP réalisée par l'Université du Michigan.
Un annuaire permet de stocker des données légèrement typées, organisées selon des classes particulières et présentées dans un arbre. L'exemple le plus commun, dont il tire son nom est l'annuaire de personnes. Mais on peut y stocker bien d'autres choses : des comptes Unix, des données personnelles (ce qu'on peut trouver dans un carnet d'adresses, mais aussi les photos des personnes, etc.), des données sur des objets plus ou moins abstraits, comme des données d'identification, des certificats (la distribution de listes de révocation de certificat peut se faire par LDAP), un parc matériel, et plus généralement tout ce qui peut être nommé et à qui on peut attacher des informations. Voyons comment procéder après une petite introduction, et comment Perl va pouvoir nous aider.
Le principe de l'annuaire n'est pas à confondre avec une base de données relationnelle dont l'objectif est différent. Un annuaire est d'abord conçu pour recevoir beaucoup plus de requêtes en lecture qu'en écriture. Une base de données a d'autres objectifs comme un typage fort et une rapidité d'accès en lecture comme en écriture.
Un annuaire permet donc de stocker des objets, auxquels on peut attacher des attributs (qui sont typés), organisés dans un arbre. Il existe une représentation normalisée des données des objets, le format LDIF.
Un autre avantage des annuaires sur les bases de données est la facilité de mise en œuvre de la réplication. En gros, à chaque modification dans l'annuaire (qui sont minimes par rapport aux accès en lecture, rappelons-le), ces modifications sont journalisées et reportées dans les annuaires secondaires, ou esclaves.
Sur ce dernier point, si l'on fait un parallèle avec les DNS, le fonctionnement est un peu différent : il n'y a pas la notion de transfert de zones (on prend toute la base de données pour l'envoyer à son collègue), mais juste la notification d'un changement (avec la matière du changement). Nous verrons plus loin que la mise en œuvre de la réplication est relativement simple, mais nécessite une initialisation manuelle. Un script peut faciliter la chose.
LDIF : LDAP Data Interchange Format. C'est le format de fichier permettant le chargement et la mise à jour de données dans un annuaire LDAP.
Par exemple :
# debut dn: dc=example,dc=com dc: example objectClass: top objectClass: domain dn: cn=Manager, dc=example,dc=com objectClass: organizationalRole cn: Manager # fin
Noter que le séparateur entre deux objets est une ligne vide.
Nous verrons plus loin ce que sont les classes d'objets (objectClass). Disons simplement pour le moment qu'une classe définit les différents attributs qu'un objet peut ou doit posséder.
Le DN est le distinguished name, à savoir le nom de l'objet dans
l'annuaire. C'est ce nom qui permet de retrouver de façon unique un objet dans
l'arbre des objets. Un objet possède donc toujours un DN, qui reprend son
RDN (relative dn). Ici, le RDN de dc=example, dc=com est
dc=example et cn=Manager pour le second enregistrement. À noter que le
RDN doit être spécifié tant dans l'objet que dans le DN.
Notez aussi que des espaces peuvent apparaître dans un DN, il ne sont pas
significatifs autour des virgules, et que si un DN est unique sur l'annuaire, il
n'en est pas de même pour le RDN. Sauf chez Microsoft dans Active Directory
Server. Mais aussi dans POSIX où il vaut mieux éviter d'avoir deux comptes ayant
le même UID (au sens LDAP) dans l'arbre des comptes. Le tout est de savoir ce
que l'on fait.
Quelques classes d'objets :
o : organization.
Cette classe permet de définir le nom de la société ou
association qui gère l'annuaire. Elle peut constituer une racine pour ce même
annuaire, avec des ou en dessous.
ou : organizationalUnit.
Un sous-ensemble d'une organisation. On pourrait le traduire en français par un service, une entité, un secteur d'une société.
dc : domainComponent.
Composant de nom de domaine (au sens DNS du terme). Le
com ou example dans example.com
person : schéma standard pour une personne.
Elle permet de définir une personne par son nom et son prénom (a minima), ainsi que, de façon optionnelle, un mot de passe, un numéro de téléphone, et une description de la personne.
Les classes d'objets permettent donc de regrouper les objets de même type, avec
un plus par rapport à une base de données : un objet peut appartenir à
plusieurs classes en même temps. Ce qui permet de fusionner, autour du même nom,
des données de person, de posixAccount (cette personne a un compte Unix),
de sambaSamAccount (elle a aussi un compte Samba), etc.
Un point à garder en mémoire est que les classes peuvent être de plusieurs types : ABSTRACT, STRUCTURAL et AUXILIARY. Dans la pratique, on utilisera essentiellement les deux dernières. Ce typage va nous permettre de définir des héritages entre classes.
Le type ABSTRACT permet juste de définir une classe dont doivent dériver d'autres classes. Une classe de type ABSTRACT ne peut avoir aucune instance d'objet dans l'annuaire.
Le type STRUCTURAL permet de définir une classe qui dérive d'une autre, la
classe racine étant la classe top (elle-même de type ABSTRACT). Le point
important ici est que dans l'instanciation d'un objet (dans son écriture LDIF,
par exemple), on doit spécifier l'entière hiérarchie des classes. Comme ici
dans notre exemple, où le domain descend de top. Ce mécanisme est
peut-être un peu contraignant (surtout si vous avez à migrer un annuaire
OpenLDAP 2.0 vers un 2.1 ou un 2.2, car la version 2.0 ne vous obligeait pas à
spécifier toute la hiérarchie d'objets), mais permet une chose importante :
ne pas mélanger torchons et serviettes. Imaginez en effet que nous ayons à
définir des utilisateurs, mais aussi des groupes. Cela ferait mauvais effet de
ne serait-ce que pouvoir mélanger les genres, et d'avoir un objet qui soit à la
fois un groupe et un utilisateur. Mais comme les classes afférentes aux groupes
et utilisateurs sont structurelles, elles ne peuvent donc être mélangées.
Il existe le dernier type de classe, AUXILIARY, qui permet de s'affranchir de ce mécanisme d'héritage, et d'attribuer des données complémentaires (« auxiliaires » dirait-on en bon franglais) à un objet.
Pour en finir avec les classes, sachez que bon nombre de classes sont définies en standard dans un certain nombre de RFC (comme les RFC 2252 et 2256). Si l'on fait un parallèle (pas si anodin que ça) avec SNMP, on peut considérer les classes comme des MIB SNMP (cf. Linux Magazine France n°43 d'octobre 2002), que l'on peut créer soi-même, ou dont on peut utiliser les MIB standards comme la MIB-II (RFC 1213).
Les attributs sont donc définissables pour un objet en fonction de la classe à laquelle l'objet appartient.
Le typage est relativement faible contrairement à un SGBD. Ou plutôt, il sert un autre dessein : l'interopérabilité. Les types sont en effet spécifiques aux annuaires, et permettent de stocker essentiellement des données alphanumériques, voire des données binaires. Mais il n'est pas complètement dans le rôle de l'annuaire de vérifier ces types. Sur un SGBD, si.
Il existe une cinquantaine de types de données, certains génériques, comme « DirectoryString » (chaîne de caractères UTF-8), « INTEGER » ou « Binary String », d'autres limités à des usages spécifiques, comme « DN » (Distinguished Name, le nom d'un objet dans un annuaire) ou « JPEG » (image au format JPEG).
Tous les types sont définis dans la RFC 2252. Nous verrons plus loin, dans l'écriture d'un schéma, que ces syntaxes (le nom des types LDAP) sont référencées par des OID (oui, les mêmes OID ASN-1 que pour SNMP, mais dans un espace de nommage différent).
L'endroit où se définissent attributs et classes d'objets, qu'ils soient standards ou de votre fait, s'appelle un schéma.
Si vous avez un OpenLDAP à votre disposition, via les paquetages standards de
votre distribution Linux, vous pouvez y jeter un coup d'œil. Ils sont dans
/etc/openldap/schema/ ou dans /usr/share/openldap/schema/. Au pire, un
locate schema vous dira où ils se trouvent.
Voici un exemple de définition de classe (au format OpenLDAP), tiré du schéma Samba :
objectclass ( 1.3.6.1.4.1.7165.2.2.6 NAME 'sambaSamAccount' SUP top AUXILIARY
DESC 'Samba 3.0 Auxilary SAM Account'
MUST ( uid $ sambaSID )
MAY ( cn $ sambaLMPassword $ sambaNTPassword $ sambaPwdLastSet $
sambaLogonTime $ sambaLogoffTime $ sambaKickoffTime $
sambaPwdCanChange $ sambaPwdMustChange $ sambaAcctFlags $
displayName $ sambaHomePath $ sambaHomeDrive $ sambaLogonScript $
sambaProfilePath $ description $ sambaUserWorkstations $
sambaPrimaryGroupSID $ sambaDomainName $ sambaMungedDial))
Les attributs vus ici viennent donc soit du schéma sambaSamAccount (ceux
préfixés par « samba »), les autres de schémas autres comme posixAccount
ou person.
Voici, toujours tiré du même schéma, la définition de quelques attributs :
##
## Account flags in string format ([UWDX ])
##
attributetype ( 1.3.6.1.4.1.7165.2.1.26 NAME 'sambaAcctFlags'
DESC 'Account Flags'
EQUALITY caseIgnoreIA5Match
SYNTAX 1.3.6.1.4.1.1466.115.121.1.26{16} SINGLE-VALUE )
##
## Password timestamps & policies
##
attributetype ( 1.3.6.1.4.1.7165.2.1.27 NAME 'sambaPwdLastSet'
DESC 'Timestamp of the last password update'
EQUALITY integerMatch
SYNTAX 1.3.6.1.4.1.1466.115.121.1.27 SINGLE-VALUE )
On remarquera la définition de la syntaxe, qui se fait par le biais d'un OID. Encore une fois, la correspondance entre OID et syntaxe associée se trouve dans la RFC 2252.
Contrairement aux bases de données, où l'on utilise régulièrement des identifiants uniques d'enregistrements (comme des numéros en auto-incrémentation), l'identifiant d'un objet dans LDAP est son nom.
Et ce nom est ce qu'on appelle un DN (Distinguished Name, nom unique,
rappelons-le - et pas nom distingué). Il est forcément unique sur l'annuaire,
car il comprend un des attributs obligatoires de la classe principale de l'objet
(comme CN=Fenal ou UID=jerome), et surtout toute la liste des OU (cf.
un peu plus bas) et autres organisations (O) et composants de nom de domaine
(dc=com) jusqu'à la racine de l'arbre des données.
Le DN d'un objet peut donc être mis dans un attribut d'un autre objet,
signifiant ainsi le lien.
Les données sont organisées dans un arbre, qui part de la racine de l'annuaire, dite RootDSE, jusqu'à tout objet considéré dans l'annuaire.
On peut organiser un annuaire de différentes façons.
Tout d'abord, on utilise rarement (comprendre : jamais) la racine RootDSE comme véritable racine de son propre annuaire. On commence toujours à un niveau en dessous défini selon son bon plaisir. On peut utiliser, comme dans l'exemple ci-dessus, une racine façon domaine DNS (example.com), mais on pourrait tout aussi bien imaginer une organisation (la société Example) en racine. Cela donnerait :
dn: o=Example o: example objectClass: top objectClass: organization
Une discussion a eu lieu l'an dernier sur la liste LDAP sur la bonne manière de faire. Vous pouvez la trouver là : http://www.openldap.org/lists/openldap-software/200311/msg00338.html.
En gros, pourvu que vous soyez cohérent avec vous même, n'importe quelle racine pourra convenir. Il sera toujours possible de vous mettre d'accord, voire de ré-écrire et ré-importer un annuaire tiers pour l'interfacer avec le vôtre.
LDAP supporte deux méthodes d'accès aux données d'un annuaire : le mode authentifié, et le mode anonyme.
Le mode anonyme peut a minima permettre de se connecter en tant qu'utilisateur authentifié, voire, si les ACL (Listes de Contrôle d'Accès) de l'annuaire le permettent, de lire un contenu minimal dans l'annuaire.
Le mode authentifié, comme dans tout autre système gérant des données, permettra par ailleurs de spécifier des droits particuliers (lecture, écriture, authentification) à un utilisateur ou à un groupe d'utilisateurs.
Pour insérer les données définies plus haut, la simple commande suivante suffit :
$ ldapadd -c -x -h localhost -D "cn=Manager,dc=example,dc=com" -W -f base.ldif
L'option -c permet de continuer sur des erreurs (un enregistrement défini
dans le fichier LDIF est déjà présent dans l'annuaire). L'option -x permet
de s'affranchir de l'authentification SASL, et n'avoir qu'à spécifier le mot de
passe. -D indique le DN du compte qui se connecte. -W fera que
ldapadd demandera le mot de passe du Manager. Enfin, -f indiquera le nom
du fichier LDIF à insérer.
$ ldapadd -c -x -h localhost -D "cn=Manager,dc=example,dc=com" -W -f base.ldif Enter LDAP Password: adding new entry "dc=example,dc=com" adding new entry "cn=Manager, dc=example,dc=com" $ ldapadd -c -x -h localhost -D "cn=Manager,dc=example,dc=com" -W -f ou.ldif Enter LDAP Password: adding new entry "ou=People,dc=example,dc=com" adding new entry "ou=Paris,ou=People,dc=example,dc=com" adding new entry "ou=London,ou=People,dc=example,dc=com" adding new entry "ou=Bath,ou=People,dc=example,dc=com" adding new entry "ou=Mongueurs,ou=People,dc=example,dc=com" adding new entry "ou=Group,dc=example,dc=com" adding new entry "ou=Computers,dc=example,dc=com"
Le fichier ou.ldif contient les entrées suivantes :
dn: ou=People,dc=example,dc=com ou: People objectclass: top objectclass: organizationalUnit dn: ou=Paris,ou=People,dc=example,dc=com ou: Paris objectclass: top objectclass: organizationalUnit dn: ou=London,ou=People,dc=example,dc=com ou: London objectclass: top objectclass: organizationalUnit dn: ou=Bath,ou=People,dc=example,dc=com ou: Bath objectclass: top objectclass: organizationalUnit dn: ou=Mongueurs,ou=People,dc=example,dc=com ou: Mongueurs objectclass: top objectclass: organizationalUnit dn: ou=Group,dc=example,dc=com ou: Group objectclass: top objectclass: organizationalUnit dn: ou=Computers,dc=example,dc=com ou: Computers objectclass: top objectclass: organizationalUnit
L'arbre des données (DIT) résultant est le suivant :
dc=com
|
dc=example
/ | \____
/ | \
/ | \
ou=People ou=Group ou=Computers
/ / \ \
/ | | \
/ | | \
/ | | \
/ | | \____
/ / \ \
/ / \ \
ou=Paris ou=London ou=Bath ou=Mongueurs
Le fichier contenant les comptes contient à peu près ce qui suit :
#!/usr/bin/perl -w use strict; my %lo = ( ymmv => 'Paris', grinder => 'Paris', book => 'Paris', sniper => 'Paris', nicholas => 'London', leon => 'Bath' ); my $uid=1000; foreach (keys %lo) { my $pass=crypt("yo $_", ('.','/',0..9,'A'..'Z','a'..'z')[rand 64][rand 64]); my $city=$lo{$_}; print << "EOF"; dn: uid=$_,ou=$city,ou=People, dc=example,dc=com objectClass: top objectClass: Person objectClass: inetOrgPerson objectClass: posixAccount objectClass: shadowAccount userPassword: $pass uid: $_ uidNumber: $uid cn: $_ loginShell: /bin/bash gidNumber: 513 gecos: Charlie $_ description: System User homeDirectory: /home/$_ sn: $_ EOF $uid++; }
Rien de bien transcendant ici, hormis la construction du sel, pour laquelle on
indexe un tableau (constitué des caractères '.', '/', des chiffres de 0 à
9, ainsi des lettres de A à Z en majuscules et minuscules) avec le résultat de la
fonction rand qui fournira un résultat variant de 0 à 63. Or le tableau
comporte bien 2 + 10 + 26 + 26 soit 64 valeurs. Et on en prend une tranche de
deux.
Ce qui donne à l'insertion :
$ ldapadd -c -x -W -D cn=Manager,dc=example,dc=com -H ldaps://ldap1.example.com/ -f comptes.ldif Enter LDAP Password: adding new entry "uid=grinder,ou=Paris,ou=People, dc=example,dc=com" adding new entry "uid=nicholas,ou=London,ou=People, dc=example,dc=com" adding new entry "uid=sniper,ou=Paris,ou=People, dc=example,dc=com" adding new entry "uid=leon,ou=Bath,ou=People, dc=example,dc=com" adding new entry "uid=ymmv,ou=Paris,ou=People, dc=example,dc=com" adding new entry "uid=book,ou=Paris,ou=People, dc=example,dc=com"
Les lignes vides ont été enlevées pour plus de concision.
Pour les groupes, pas besoin de générer automatiquement, ça peut encore se faire à la main :
dn: cn=stout,ou=Group,dc=example,dc=com cn: stout gidNumber: 10001 memberUid: book memberUid: sniper memberUid: grinder description: Buveurs de stout objectClass: posixGroup dn: cn=tea,ou=Group,dc=example,dc=com cn: tea gidNumber: 10002 memberUid: nicholas memberUid: leon memberUid: ymmv memberUid: book description: Buveurs de the objectClass: posixGroup dn: cn=cristal,ou=Group,dc=example,dc=com cn: cristal gidNumber: 10003 memberUid: nicholas memberUid: ymmv description: Buveurs de blonde allemande objectClass: posixGroup
Un autre avantage de LDAP est la flexibilité de son mode d'interrogation.
On a parlé ci-dessus de l'arbre contenant les données (DIT), il va nous permettre de limiter la recherche.
La recherche dans un annuaire, en plus de la spécification d'attributs, nous permet de spécifier deux paramètres particuliers :
base de la recherche :
Le point de départ, dans l'arbre des informations de l'annuaire (DIT), de la recherche, ce qui nous permet de limiter une recherche à une sous-branche de l'arbre ;
scope de recherche :
La façon dont la recherche va pouvoir descendre dans les branches de l'arbre.
Pour cela, plusieurs possibilités sont offertes par LDAP, base, sub et
one :
scope=base :
Permet de faire une recherche dans la base de l'annuaire, et retourne toutes les entrées trouvées. Ce type de requête n'est pas utile en temps normal (elle est utilisée par exemple pour obtenir des informations sur le schéma) ;
scope=sub :
Permet de faire une recherche à partir du nœud spécifié par la base, dans le nœud courant, mais aussi dans tous les nœuds en dessous. On pourrait le penser comme une recherche récursive dans toutes les branches du sous-arbre prenant racine à la base considérée ;
scope=one :
Permet de faire une recherche à partir du nœud spécifié par la base, uniquement
sur le niveau courant. Cela évite de descendre visiter les OU s'il n'y en a
pas besoin.
En plus des limites « spatiales » que l'on peut imposer à notre recherche, on peut aussi (fort heureusement) spécifier des données à rechercher. Cela se fait dans les filtres LDAP. Contrairement aux habitudes en matière de développement en langage de haut-niveau, la syntaxe des filtres utilise des opérateurs préfixés, ce afin d'éviter toute ambiguïté syntaxique. Après ces précisions, gardez à l'esprit que les filtres sont donc relativement simples, et le mieux est de le voir sur un exemple :
(&((|(objectClass=person)(objectClass=posixAccount))(uid=jerome)))
Si l'on éclate ce filtre sur plusieurs lignes, cela donne :
(
& (
(
| (objectClass=person)
(objectClass=posixAccount)
)
(uid=jerome)
)
)
Soit : trouve-moi les objets de classe person ou posixAccount dont
l'attribut uid est « jerome » (attention, ici, l'attribut uid
représente l'identifiant de l'utilisateur, le nom de son compte, et non l'uid
au sens POSIX qui sera uidNumber).
Ces filtres peuvent donc être utilisés dans vos requêtes sur l'annuaire.
Rappelons une fois encore que le but d'un annuaire est d'être interrogé.
Les requêtes peuvent être faites manuellement, via la commande ldapsearch, ou
par vos applications, qu'elles soient en Perl ou en C. La représentation éclatée
d'un filtre présentée ci-dessus n'a pour but que de vous montrer sa construction.
La forme uniligne sera la seule utilisable dans les faits.
$ ldapsearch -x -s sub -W -D cn=Manager,dc=example,dc=com -H ldap://localhost/ "(ou=Paris)" -LLL Enter LDAP Password: *****¶ dn: ou=Paris,ou=People,dc=example,dc=com objectClass: top objectClass: organizationalUnit ou: Paris description: Paris users
Nous avons recherché l'objet par son nom, en l'occurrence l'OU Paris.
L'option -LLL permet de se passer des commentaires insérés dans la réponse,
et d'obtenir ainsi du LDIF réutilisable facilement.
On veut tous les noms des personnes de Paris :
$ ldapsearch -x -s sub -b 'ou=Paris,ou=People,dc=example,dc=com' -W -D cn=Manager,dc=example,dc=com "(objectclass=posixAccount)" -LLL dn Enter LDAP Password: *****¶ dn: uid=ymmv,ou=Paris,ou=People,dc=example,dc=com dn: uid=grinder,ou=Paris,ou=People,dc=example,dc=com dn: uid=sniper,ou=Paris,ou=People,dc=example,dc=com dn: uid=book,ou=Paris,ou=People,dc=example,dc=com
Le paramètre dn passé à ldapsearch permet de n'avoir que les DN dans la
sortie.
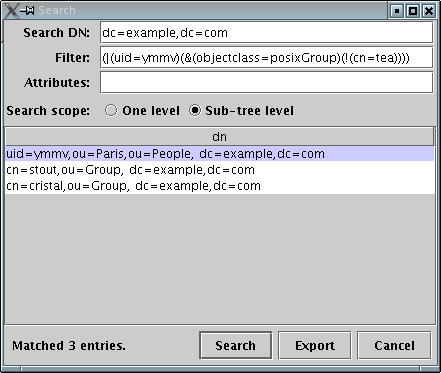
$ ldapsearch -x -s sub -b 'dc=example,dc=com' -W -D cn=Manager,dc=example,dc=com '(|(uid=ymmv)(&(objectclass=posixGroup)(!(cn=tea))))' dn -LLL Enter LDAP Password: *****¶ dn: uid=ymmv,ou=Paris,ou=People,dc=example,dc=com dn: cn=stout,ou=Group,dc=example,dc=com dn: cn=cristal,ou=Group,dc=example,dc=com
Cette requête, qui ne sert pas à grand chose pour un cas réel, permet de
demander l'utilisateur uid=ymmv, ainsi que tous les groupes de classe
posixGroup sauf celui des buveurs de thé.
La même requête dans ldapbrowser+editor :
OpenLDAP est un annuaire libre mettant en œuvre le protocole LDAP, sous une licence qui semble équivalente à la licence BSD révisée (sans clause de publicité).
Il est dérivé du serveur LDAP de l'Université du Michigan, et a largement évolué depuis.
Je ne m'étendrai pas sur les arcanes de la compilation d'OpenLDAP, car elle pourrait faire l'objet d'un article à part entière. Sachez simplement qu'il vous faudra les logiciels suivants :
Les dernières versions (2.1 et 2.2 à l'heure où j'écris) utilisent cette base de
données en support (backend). Elle a l'immense avantage d'être
transactionnelle, à savoir qu'elle gère un mécanisme de journalisation des mises
à jour des données, et permet grâce à lui une haute-disponibilité, contrairement
à d'autres mécanismes comme le support ldbm.
À noter que cette bibliothèque est souvent intégrée à votre distribution GNU/Linux, mais pas toujours dans la version requise par OpenLDAP. Et c'est là que les ennuis commencent car il vous faudra la compiler spécifiquement pour pouvoir compiler ensuite OpenLDAP.
LDAP est un des protocoles, comme HTTP, à pouvoir être encapsulé nativement dans
SSL/TLS. Pour sécuriser les échanges entre clients et annuaire, il vous faudra
donc compiler l'annuaire avec OpenSSL. Le nom du protocole façon URL devient
ldaps au lieu de ldap pour la version non SSL.
Utilisez plutôt les paquetages disponibles (apt-get install, urpmi
ou encore yum install, dans un ordre alphabétique) dans votre distribution ou
utilisez ceux de Jehan Procaccia de l'INT (cf. § Liens).
OpenLDAP 2.1 est la première version à peu près propre de OpenLDAP (entendons
nous bien, ce n'est pas péjoratif, le développement d'un tel logiciel est
conséquent). Ce terme propre s'applique essentiellement au maintien des
contraintes d'intégrité entre types de classes d'objets (pour les classes dites
STRUCTURAL, voir plus loin).
OpenLDAP permet d'utiliser plusieurs sources de données, en plus des classiques bases internes, à présenter via une interface LDAP :
Un serveur DNS qui sera vu au travers d'un annuaire LDAP ;
Les informations sur le fonctionnement du moteur LDAP fournies au travers du protocole. Cette possibilité est spécifique à OpenLDAP ;
Un moyen de construire un serveur mandataire inversé (reverse proxy pour les anglicistes), i.e. un serveur qui analyse les requêtes qu'on lui passe et les retranscrit pour un autre serveur (un bon moyen de s'assurer de la validité -- pour autant que votre OpenLDAP en frontal n'ait pas été compromis -- du protocole LDAP que vous passez à votre annuaire propriétaire) ;
Permet la construction d'un méta-annuaire. Similaire au mandataire, il aggrège plusieurs autres annuaires en définissant les sous-arbres d'informations (DIT) où viennent se brancher les différentes sources pour les présenter aux clients ;
Les informations fournies sont piochées dans un fichier de type /etc/passwd ;
La source de données, plutôt que d'être gérée par un moteur de base de données directement lié à OpenLDAP (ce qui évite d'avoir plusieurs processus différents pour offrir le service), est stockée dans une base externe SQL.
Le serveur LDAP est slapd.
Le co-serveur de réplication est slurpd.
Dans ce qui suit, nous allons détailler quelque peu la configuration par défaut
de slapd sur la Mandrake 10 de mon portable personnel, où je mettrai d'abord
le contenu du fichier, histoire de vous laisser un peu deviner, puis quelques
explications sur les lignes qui précédent. Ça peut vous sembler bizarre, mais
c'est comme ça.
include /usr/share/openldap/schema/core.schema include /usr/share/openldap/schema/cosine.schema include /usr/share/openldap/schema/corba.schema include /usr/share/openldap/schema/inetorgperson.schema include /usr/share/openldap/schema/java.schema include /usr/share/openldap/schema/krb5-kdc.schema include /usr/share/openldap/schema/kerberosobject.schema include /usr/share/openldap/schema/misc.schema include /usr/share/openldap/schema/nis.schema include /usr/share/openldap/schema/openldap.schema include /usr/share/openldap/schema/autofs.schema include /usr/share/openldap/schema/samba.schema include /usr/share/openldap/schema/kolab.schema include /etc/openldap/schema/local.schema
Ce sont les inclusions des schémas LDAP utilisables sur ce serveur. Il importe de définir ici ceux que vous voulez employer. Nous garderons ceux par défaut. Les unixiens reconnaîtront différentes sources de données distribuées Unix comme nis.schema et autofs.schema, les schémas standards LDAP étant dans core.schema, cosine.schema et inetorgperson.schema. Les autres (dont samba.schema et kerberosobject.schema) sont des schémas supplémentaires.
include /etc/openldap/slapd.access.conf
Ceci est juste une inclusion de définitions d'ACL complémentaires sur les objets de l'annuaire.
pidfile /var/run/ldap/slapd.pid argsfile /var/run/ldap/slapd.args
De quoi savoir où le serveur slapd doit stocker le numéro du processus pour
les scripts de démarrage et d'arrêt sachent faire leur travail, ainsi que les
arguments qui ont été passés à slapd pour le lancer.
modulepath /usr/lib/openldap
L'emplacement des modules (bibliothèques dynamiques) utilisables par OpenLDAP, essentiellement les différents supports (backend).
TLSCertificateFile /etc/ssl/openldap/ldap.pem TLSCertificateKeyFile /etc/ssl/openldap/ldap.pem TLSCACertificateFile /etc/ssl/openldap/ldap.pem
Là où sont stockés les certificats SSL pour le protocole ldaps.
À partir du mot-clé database qui suit, la configuration ne vaut que pour la
base considérée (ici, dc=example,dc=com). Cela permet de faire gérer
plusieurs annuaires, pourvu qu'ils aient des racines différentes, en ajoutant
une section database supplémentaire.
database bdb
Début de spécification d'une base de données, ainsi que son type. Toutes les
directives qui suivent se rapportent uniquement à la base de données qui débute
ainsi, jusqu'à la prochaine directive database ou la fin du fichier.
suffix "dc=example,dc=com"
Le positionnement dans l'arbre des informations qui seront gérées par cette base.
rootdn "cn=Manager,dc=example,dc=com"
Le nom du super-utilisateur pour cette base. Pour bien faire, il faut aussi l'insérer dans l'annuaire.
rootpw secret
Le mot de passe de ce monsieur. Ici, la chaîne est en clair (lisez :
ne le faites jamais, même en protégeant le fichier
/etc/openldap/slapd.conf), mais peut aussi être spécifiée avec un hash DES
(ie. comme dans /etc/shadow : {crypt}ijFYNcSNctBYg, à peine plus
acceptable que le texte pur ; l'idéal étant le SSHA, ou tout autre
algorithme de chiffrement fort).
Le générateur de hash de mot de passe pour LDAP est slappasswd :
$ /usr/sbin/slappasswd -h '{SSHA}' -s secret -v
{SSHA}H1mqncWN0AUgHu15O5+ECKjulFRPn8LF
$ /usr/sbin/slappasswd -h '{MD5}' -s secret -v
{MD5}Xr4ilOzQ4PCOq3aQ0qbuaQ==
Les types de chiffrements sont fort bien expliqués dans la page de manuel
slappasswd(8C). Rapidement, {MD5} et {SHA} sont ce qu'on pense qu'ils sont,
{SMD5} et {SSHA} sont exactement les mêmes, mais avec une graine (seed), de
façon à augmenter la complexité du décryptage par force brute. Pour mémoire,
l'encodage DES de /etc/passwd fonctionne sur le même principe, les deux
premiers caractères de la chaîne chiffrée correspondent à cette graine.
Oh, j'oubliais, l'option -s permet de passer le mot de passe sur la ligne de
commande, ce que vous éviterez (vous n'avez pas envie qu'on voie votre mot de
passe avec la commande ps(1) ou dans l'historique des commandes).
Retour au fichier de configuration :
directory /var/lib/ldap
Le répertoire où seront stockées les données.
index objectClass,uid,uidNumber,gidNumber eq index cn,mail,surname,givenname eq,subinitial
Les index à créer sur les attributs pour accélérer les recherches.
loglevel 256
La définition de la verbosité de slapd, pour qu'il ne signifie que les
connexions, les opérations et les résultats. La page de manuel de
slapd.conf(5), section loglevel vous donnera les valeurs à additionner (ou
inclusif plus exactement) pour avoir d'autres informations.
access to attr=userPassword
by self write
by anonymous auth
by dn="uid=root,ou=People,dc=example,dc=com" write
by * none
access to *
by dn="uid=root,ou=People,dc=example,dc=com" write
by * read
Les quelques ACL de base pour la mise à jour des mots de passe et la gestion des comptes POSIX.
La place manque quelque peu pour parler plus avant des ACL. Sachez cependant que les définitions en sont linéaires (on matche et on sort ou on continue jusqu'à la fin), donc que l'ordre de spécification de ces ACL est important.
La documentation, quoique succinte, est bien faite, et vous permettra de voir les différentes façon de faire. N'oubliez pas de tester vos ACL avant toute mise en production, surtout dans le cas d'un serveur d'authentification. Il ne s'agit pas de rendre publics des mots de passe, surtout après la tenue de la conférence Crypto 2004, ou encore la liste des employés ou adhérents de votre organisation pour un bon vieux spam...
Les quelques clients proposés ici sont dignes d'intérêt, que ce soit pour ce qu'ils sont en mesure de proposer actuellement, ou pour les promesses qu'ils seront à même de satisfaire dans quelque temps.
http://www-unix.mcs.anl.gov/~gawor/ldap/
La référence en la matière. Bien que non libre, son source Java est disponible. Cependant, il n'a pas évolué depuis 2001, mais reste toujours fonctionnel, le glisser-déposer (drag'n drop) étant une killer-feature par rapport au suivant.
Le coût d'acquisition est minime pour un utilisateur simple : 35 dollars. Plus d'informations sur http://www.softwareshop.anl.gov/ldapbrowser.html.
Issu de l'ouverture par Computer Associates d'un outil initialement développé par le laboratoire de dévelopemment de eTrust Directory. Écrit lui aussi en Java, complémentaire à LBE sur certaines opérations.
Outil libre développé avec GTK, c'est l'outil le plus complet et à mon sens le plus pratique que j'ai vu, bien que n'ayant pas travaillé avec (c'est l'inconvénient de travailler sur le PC fourni par votre employeur, vous n'avez pas toujours le système d'exploitation que vous aimeriez utiliser ;-).
Il gère des templates, permet facilement d'ajouter des attributs car il sait interroger le schéma, bref, au premier coup d'&oeil;, ça ressemble à du bonheur.
Cependant, quelques fonctionnalités pratiques comme le renommage d'un objet intermédiaire (ie. non feuille) d'un arbre ne sont pas gérées, de même que le glisser-déposer d'un objet sur un autre pour le déplacer ou fusionner les deux objets considérés (ce que sait faire ldapbrowser+editor).
Gestionnaire d'annuaire écrit en PHP essentiellement pour gérer des comptes POSIX et Samba. Jamais testé personnellement (il nécessite des options de compilation spécifiques pour PHP, mes Linux sont trop vieux, le FreeBSD trop jeune -- les ports n'étaient pas à jour pour la 5.2 --, et le temps me manquait), mais il paraît très pratique.
http://www.easter-eggs.org/article_350_Mise_a_jour_de_Ldapsaisie.html et son successeur Saga : http://labs.libre-entreprise.org/projects/saga/.
Prometteur, mais pas testé directement, car un poil buggé sur la version que j'ai tenté de tester. Il est en cours de réécriture par ses auteurs Mickaël Parienti et Thierry Dulieu de la SSLL Easter Eggs. Merci à Mickaël pour son support, que je n'ai malheureusement pas eu le temps d'exploiter.
Le gros avantage de ldapsaisie ou saga est d'avoir une gestion de template relativement facile à étendre, tout en minimisant le développement. Cela permettrait de mettre une interface de modifications sur l'annuaire à la disposition de tout intervenant, en spécifiant ce qu'il est possible ou pas de faire, sur tel ou tel objet, sur tel ou tel attribut.
... nous parlerons des utilisations avancées de OpenLDAP, en particulier la mise en œuvre de SSL/TLS, la réplication et l'écriture d'un schéma.
L'annuaire libre. http://www.openldap.org/
La base de données transactionnelle embarquée dans OpenLDAP : http://www.sleepycat.com/.
Je vous donne ici le nom de la liste, ainsi que sa localisation dans l'excellent
moteur d'archivage et de présentation en NNTP de lidies, j'ai nommé
Gmane.org, ainsi que le site Web du gestionnaire de liste.
La liste en français sur LDAP. On y parle de OpenLDAP, mais pas seulement, de Samba, de SSO et autres joyeusetés. Une source à ne pas rater, et de qualité. Un peu de bruit de temps en temps, mais elle n'en reste pas moins intéressante.
Plusieurs listes sont mises à disposition par le projet OpenLDAP. Attention, tournez sept fois votre langue dans votre clavier avant de poster une question, car la liste peut être chaude avec les nouveaux venus. Il est dommage de voir que certaines personnes du libre (développeurs et/ou utilisateurs) en sont restées à un stage primitif. Mais ça leur passera.
<jfenal@free.fr> et <jerome.fenal@logicacmg.com>.
Jérôme Fenal est utilisateur de GNU/Linux depuis 1994, de divers Unix ou Unix-like (Domain/OS) depuis un peu plus longtemps.
Membre depuis peu des Mongueurs de Perl parisiens, après des années (depuis la création ?) à m'être fait tanner par Philippe « BooK » Bruhat pour y venir.
Merci aux Mongueurs Marseillais, Lyonnais et Parisiens qui ont assuré la relecture de cet article.
Cet article a été écrit sous Linux, avec [g]vim, en pod (Plain Old Documentation).
![[IE7, par Dean Edwards]](/images/ie7.gif)
![[Validation du HTML]](/images/xhtml.gif)
![[Validation du CSS]](/images/css.gif)
Copyright © Les Mongueurs de Perl, 2001-2011
pour le site.
Les auteurs conservent le copyright de leurs articles.